Why and What of DSA?
I am Jyotiprakash, a deeply driven computer systems engineer, software developer, teacher, and philosopher. With a decade of professional experience, I have contributed to various cutting-edge software products in network security, mobile apps, and healthcare software at renowned companies like Oracle, Yahoo, and Epic. My academic journey has taken me to prestigious institutions such as the University of Wisconsin-Madison and BITS Pilani in India, where I consistently ranked among the top of my class.
At my core, I am a computer enthusiast with a profound interest in understanding the intricacies of computer programming. My skills are not limited to application programming in Java; I have also delved deeply into computer hardware, learning about various architectures, low-level assembly programming, Linux kernel implementation, and writing device drivers. The contributions of Linus Torvalds, Ken Thompson, and Dennis Ritchie—who revolutionized the computer industry—inspire me. I believe that real contributions to computer science are made by mastering all levels of abstraction and understanding systems inside out.
In addition to my professional pursuits, I am passionate about teaching and sharing knowledge. I have spent two years as a teaching assistant at UW Madison, where I taught complex concepts in operating systems, computer graphics, and data structures to both graduate and undergraduate students. Currently, I am an assistant professor at KIIT, Bhubaneswar, where I continue to teach computer science to undergraduate and graduate students. I am also working on writing a few free books on systems programming, as I believe in freely sharing knowledge to empower others.
Learning data structures and algorithms is fundamental for students, especially those studying computer science, for several reasons:
Foundation of Programming: Data structures (like arrays, stacks, queues, linked lists, trees, and graphs) and algorithms (like sorting and searching) are the building blocks of efficient programming. They help students understand how to organize and manage data in ways that enhance the performance of applications.
Examples:Social Media Apps: Efficient user profile management in platforms like Facebook uses hash tables to enable rapid data retrieval.
E-commerce Inventory: Arrays and tree structures optimize product searches and inventory management, making platforms like Amazon fast and user-friendly.
Problem-Solving Skills: Studying algorithms encourages students to develop strong problem-solving and analytical skills. It teaches them different ways to approach complex problems, dissect them, and find optimal solutions.
Examples:Towers of Hanoi: A classic problem solved using recursion, illustrating the power of breaking down problems into simpler sub-problems.

Maze Solving: Using graph traversal algorithms like Breadth-First Search (BFS) to find the shortest path, applicable in robotics and gaming.

Efficiency and Scalability: Knowledge of the right data structures and algorithms allows students to write programs that run faster and require less memory. This is crucial for building applications that can scale to handle a large amount of data or users.
Examples:Google Search: Utilizes complex algorithms to scan vast datasets quickly and efficiently, ensuring fast response times.
Streaming Services: Algorithms optimize data streaming and buffering in platforms like Netflix, where data efficiency directly enhances user experience.
Career Opportunities: Proficiency in data structures and algorithms is often a critical component of technical interviews, particularly for positions in major tech companies. Demonstrating strong skills in these areas can significantly enhance a candidate's job prospects.
Examples:Software Engineering Interviews: Candidates are often tested on their knowledge of efficient algorithms like quicksort or data structures like linked lists.
Data Science Roles: Understanding algorithms can help manipulate large datasets effectively, a common task in data science interviews.
Better Understanding of Advanced Topics: Many advanced topics in computer science, such as artificial intelligence, machine learning, database systems, and networking, are built upon the principles of data structures and algorithms. Understanding these basics helps students grasp more complex concepts more easily.
Examples:Artificial Intelligence: Techniques like genetic algorithms and neural networks are underpinned by basic algorithmic strategies.
Database Systems: Effective query optimization in SQL databases often uses tree-based data structures for quick retrieval.
Tool for Competitive Programming: Many students also participate in coding competitions where data structures and algorithms are heavily tested. Proficiency in these areas can lead to success in these competitions, which often provide additional career and academic opportunities.
Examples:ACM ICPC: Teams compete to solve complex problems using efficient data structures like segment trees to handle range queries and updates efficiently.
Codeforces Contests: Participants often use advanced algorithms such as dynamic programming to solve time-constrained problems.
Illustrations for motivation
Certainly! Understanding Big O, Theta (Θ), and Omega (Ω) notations is crucial for analyzing the performance of algorithms. Here's a very basic example in C using a simple algorithm: linear search. We'll use this example to explain these three concepts:
Performance of a simple algorithm
The linear search algorithm checks each element of an array sequentially until the desired value is found or the list is completely searched. Here is a simple implementation:
#include <stdio.h>
// Function to perform linear search
int linearSearch(int arr[], int n, int x) {
for (int i = 0; i < n; i++) {
if (arr[i] == x) {
return i; // Return the index where the element is found
}
}
return -1; // Return -1 if the element is not found
}
int main() {
int arr[] = {2, 3, 4, 10, 40};
int n = sizeof(arr) / sizeof(arr[0]);
int x = 10; // Element to search
int result = linearSearch(arr, n, x);
if (result != -1)
printf("Element is present at index %d", result);
else
printf("Element is not present in array");
return 0;
}
Analysis Using Big O, Theta, and Omega
Big O Notation (Upper Bound)
Explanation: Big O notation describes an upper bound of an algorithm, denoting the worst-case scenario in terms of time or space used. It provides a guarantee that the algorithm will not perform worse than the given complexity.
Application: In the case of the linear search, the worst-case scenario occurs when the element is not present in the array at all or is at the very end of the array. The algorithm will have to check every element, resulting in
ncomparisons, wherenis the size of the array.Notation: The Big O notation for linear search is O(n).
Theta Notation (Tight Bound)
Explanation: Theta notation describes a tight bound of an algorithm. It means the function will grow in proportion to
nin the average case. Theta notation gives a precise measure of complexity considering both upper and lower bounds.Application: For linear search, if we assume all elements are equally likely to be the searched value and can appear anywhere in the array, the average case scenario will also involve approximately
n/2comparisons. Thus, the growth of function calls is directly proportional ton.Notation: The Theta notation for linear search is Θ(n).
Omega Notation (Lower Bound)
Explanation: Omega notation provides a lower bound, indicating the best-case scenario. It represents the minimum amount of time or space that an algorithm will require.
Application: In the best-case scenario for linear search, the target element is right at the beginning of the array, so the search ends after just one comparison.
Notation: The Omega notation for linear search is Ω(1), indicating that, in the best case, the algorithm runs in constant time.
This C program example of a linear search effectively illustrates Big O, Theta, and Omega notations:
O(n) demonstrates that the search will not take more steps than there are elements.
Θ(n) shows that on average, the search time increases linearly with the number of elements.
Ω(1) reflects the optimal scenario where the search finds the target immediately.
A stack is a data structure that follows the Last In, First Out (LIFO) principle, where the last element added to the stack is the first one to be removed. This structure is analogous to a stack of plates; you can only add or remove the top plate. Stacks are commonly used in many programming scenarios, including expression evaluation, syntax parsing, and backtracking algorithms.
Stack Operations
Push: Add an element to the top of the stack.
Pop: Remove the top element from the stack.
Peek/Top: Look at the top element of the stack without removing it.
IsEmpty: Check if the stack is empty.
Using a Stack to Match Parentheses
Matching parentheses is a classic problem where you use a stack to check if each opening parenthesis has a corresponding closing parenthesis in expressions. Examples include mathematical expressions like (a + b) * (c + d).
Expression: ((a + b) * c) - d
Index Character Stack Action Stack Content Explanation
----- --------- ------------ ------------- -----------
0 ( Push [ '(' ] Open parenthesis, push.
1 ( Push [ '(', '(' ] Another open, push.
2 a
3 +
4 b
5 ) Pop [ '(' ] Close parenthesis, pop.
6 *
7 c
8 ) Pop [] Another close, pop.
9 -
10 d
If all goes well and the stack is empty at the end of the string traversal, it means every opening parenthesis has been properly closed in the correct order. If the stack is not empty or if a closing parenthesis is encountered when the stack is empty, it indicates an imbalance in the parentheses.
The N-Queens problem is a classic puzzle in which you must place N queens on an N×N chessboard in such a way that no two queens threaten each other. This means that no two queens can be placed in the same row, column, or diagonal.
The solution to the problem requires that each queen must be placed in a different row. By using this property, we can use a one-dimensional array board[N] where each index represents a row and the value at that index represents the column where the queen is placed. For example, if board[1] = 3, it means that a queen is placed in the second row and fourth column (since array indices typically start at 0).
Solving with Recursion and Backtracking
Recursion is used to try placing a queen in each row. Backtracking is applied to remove a queen if placing it results in no valid moves in subsequent rows.
Illustration:
Qwill represent a queen on the board..will represent an empty space.
Step-by-Step Solution
Start with an empty board:
. . . . . . . . . . . . . . . .Place a queen in the first row, first column:
Q . . . . . . . . . . . . . . .Move to the second row:
Cannot place a queen in the first column (same column as the first queen).
Cannot place a queen in the second column (diagonal to the first queen).
Try third column:
Q . . .
. . Q .
. . . .
. . . .
Move to the third row:
- First, second, and third columns are all threatened by the existing queens.
Try fourth column:
Q . . .
. . Q .
. . . Q
. . . .
Move to the fourth row:
Every column is threatened.
Backtrack: Remove the queen from the third row, fourth column.
Back in the second row, move the queen to the fourth column:
Q . . . . . . Q . . . . . . . .Try placing queens in the third row:
- First and fourth columns are threatened.
Try second column:
Q . . .
. . . Q
. Q . .
. . . .
Move to the fourth row:
- The third column is the only option:
Q . . .
. . . Q
. Q . .
. . Q .
Successful placement of all queens? Maybe we need to relook the first row!
Insertion sort iterates through an input array and removes one element per iteration, finding its place in a new sorted array until no input elements remain.
Step-by-Step Process:
Start from the second element (consider the first element to be part of the sorted list).
Compare the current element with the elements in the sorted list.
Shift all the elements in the sorted list that are greater than the current element to the right.
Insert the current element at its correct position.
Repeat until the whole list is sorted.
Consider the array [4, 3, 5, 1, 2]. We will sort this using insertion sort:
Initial array:
4, 3, 5, 1, 2
Start with the first element (4), it's sorted by default:
[4], 3, 5, 1, 2
Take the next element (3) and insert it before 4 since 3 < 4:
[3, 4], 5, 1, 2
Next, take 5. It's already in the correct position because 5 > 4:
[3, 4, 5], 1, 2
Next, take 1. It needs to be placed at the start:
[1, 3, 4, 5], 2 // Shifts 3, 4, and 5 to the right
Finally, take 2. It goes between 1 and 3:
[1, 2, 3, 4, 5] // Completed sorted array
Analysis of Cases:
Worst Case: The worst case occurs when the array is sorted in reverse order. Every insertion operation has to shift all the elements sorted so far. The number of comparisons and shifts in the worst case is
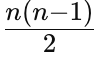
leading to a time complexity of O(n^2).
Average Case: On average, half of the elements in the sorted array need to be moved for each new element, leading to a time complexity of Θ(n^2).
Best Case: The best case occurs when the array is already sorted. Each new element in the iteration needs to be compared only once and placed in its position without any shifts. The best-case time complexity is Ω(n), where n is the number of elements in the array.
Binary search is an efficient algorithm for finding an item from a sorted list of items. It works by repeatedly dividing in half the portion of the list that could contain the item, until you've narrowed down the possible locations to just one.
How Binary Search Works:
Compare the target value to the middle element of the array.
If the target value is equal to the middle element, the search is complete.
If the target value is smaller, the search continues in the lower (left) half of the array.
If the target value is larger, the search continues in the upper (right) half of the array.
Repeat steps 1-4 until the target value is found or the search space is empty.
Consider the sorted array [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] and we want to find the value 7 using binary search:
Initial array:
1 2 3 4 5 6 7 8 9 10
Target = 7
Step 1: Compare with middle (element at index 5 -> 6)
1 2 3 4 5 [6] 7 8 9 10 // Middle element is 6, which is less than 7.
Step 2: Eliminate the left half including 6, consider the right half
7 8 9 10 // New array to consider.
Step 3: Compare with new middle (element at index 2 of new array -> 9)
7 8 [9] 10 // Middle element is 9, which is greater than 7.
Step 4: Eliminate the right half including 9, consider the left half
7 8 // New array to consider.
Step 5: Compare with new middle (element at index 1 of new array -> 8)
7 [8] // Middle element is 8, which is greater than 7.
Step 6: Eliminate the right half including 8, only one element left
[7] // Middle element is 7, which matches the target.
Analysis of Cases:
Worst Case and Average Case: The search space is halved each time, so the time complexity is O(log n), where n is the number of elements in the array. The worst case occurs when the target value is not in the array but the search continues until the search space is exhausted.
Best Case: The best case occurs when the target value is exactly at the middle of the array, which results in a time complexity of Ω(1) as only one comparison is needed.
A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child. It's a foundational concept in computer science, used in various applications from simple sorting algorithms to managing complex data structures.
Structure of a Binary Tree
Root: The top node in the tree.
Child: Nodes referenced by other nodes.
Leaf: Nodes with no children.
Depth: The length of the path from the root to the node.
Height: The depth of the deepest node.
Binary trees can be specialized further, such as in binary search trees (BSTs), where each node's left children are less than the parent node, and the right children are greater.
One practical use of binary trees is the implementation of binary search trees (BST). A BST allows efficient searching, inserting, and deleting of nodes. It is widely used in scenarios where rapid search, insertion, and deletion of items are required, such as in database indices and file systems.
Managing Usernames in a System
Consider a system where usernames need to be stored and retrieved efficiently. A binary search tree could be used to manage these usernames due to its efficient lookup, insertion, and deletion properties.
Suppose we want to manage a set of usernames: [Zara, Tim, Rob, Mia, Jan, Ava]. We insert them into a BST as follows:
Certainly! Let's build a correct Binary Search Tree (BST) for the given set of usernames: [Zara, Tim, Rob, Mia, Jan, Ava], adhering strictly to the alphabetical ordering.
- Insert 'Zara' - becomes the root.
Zara
/ \
null null
- Insert 'Tim' - goes to the left of 'Zara' because 'Tim' < 'Zara'.
Zara
/ \
Tim null
/ \
null null
- Insert 'Rob' - goes to the left of 'Tim' because 'Rob' < 'Tim'.
Zara
/ \
Tim null
/ \
Rob null
/ \
null null
- Insert 'Mia' - goes to the left of 'Rob' because 'Mia' < 'Rob'.
Zara
/ \
Tim null
/ \
Rob null
/ \
Mia null
- Insert 'Jan' - goes to the left of 'Mia' because 'Jan' < 'Mia'.
Zara
/ \
Tim null
/ \
Rob null
/ \
Mia null
/ \
Jan null
- Insert 'Ava' - goes to the left of 'Jan' because 'Ava' < 'Jan'.
Zara
/ \
Tim null
/ \
Rob null
/ \
Mia null
/ \
Jan null
/ \
Ava null
Final Tree Structure:
Zara
/ \
Tim null
/ \
Rob null
/ \
Mia null
/ \
Jan null
/ \
Ava null
To find a username like 'Ava', we would navigate the tree structure as follows:
Start at 'Zara', and since 'Ava' < 'Zara', move to the left child.
At 'Tim', since 'Ava' < 'Tim', move to the left child.
At 'Rob', since 'Ava' < 'Rob', move to the left child.
At 'Mia', since 'Ava' < 'Mia', move to the left child.
At 'Jan', since 'Ava' < 'Jan', move to the left child and find 'Ava'.
This tree exhibits a pronounced skew and imbalance to the left, primarily due to the sequential insertion of elements in descending order. At first glance, it might seem that each search operation nearly equals the number of elements (denoted as n) in the tree, akin to linear search. However, by employing techniques such as AVL or Red-Black tree balancing, the distribution of elements within the tree can be adjusted. This balancing ensures that both the left and right subtrees of each node contain roughly an equal number of elements. Consequently, search operations transform from linear to logarithmic complexity, greatly enhancing efficiency.
Depth First Search (DFS) is a fundamental search algorithm used in various applications, including traversing trees, searching through graph data structures, solving puzzles, and more. DFS explores as far as possible along each branch before backtracking, making it an excellent choice for tasks that require exploring all possibilities until a solution is found.
DFS can be implemented using recursion, which inherently uses a call stack, or explicitly using an iterative approach with a stack data structure. Here, we'll focus on the explicit stack method, which is conceptually simpler for understanding the mechanics of DFS.
Steps of DFS Using a Stack:
Push the starting node onto the stack.
While the stack is not empty:
Pop the top node.
Mark it as visited.
For each adjacent node:
- If it has not been visited, push it onto the stack.
Example: DFS on a Graph
Consider a simple graph represented as follows:
1
/ \
2 3
/ \ / \
4 5 6 7
Let's traverse this graph using DFS starting from node 1.
- Initialize Stack: Start with node 1.
Stack: [1]
- Explore Node 1: Pop 1, visit it, push its neighbors (2, 3).
Visited: 1
Stack: [3, 2]
- Explore Node 2: Pop 2, visit it, push its neighbors (4, 5).
Visited: 1, 2
Stack: [3, 5, 4]
- Explore Node 4: Pop 4, it has no neighbors to add.
Visited: 1, 2, 4
Stack: [3, 5]
- Explore Node 5: Pop 5, it has no neighbors to add.
Visited: 1, 2, 4, 5
Stack: [3]
- Explore Node 3: Pop 3, visit it, push its neighbors (6, 7).
Visited: 1, 2, 4, 5, 3
Stack: [7, 6]
- Explore Node 6: Pop 6, it has no neighbors to add.
Visited: 1, 2, 4, 5, 3, 6
Stack: [7]
- Explore Node 7: Pop 7, it has no neighbors to add.
Visited: 1, 2, 4, 5, 3, 6, 7
Stack: []
Explanation:
Stack Use: The stack controls which node to visit next. It ensures that the most recently discovered node is explored first, adhering to the depth-first principle.
Backtracking: When the stack pops a node with no unvisited neighbors, the algorithm "backtracks" to explore other branches of the graph, reflected by the next node in the stack.
Dynamic programming (DP) is a method for solving complex problems by breaking them down into simpler subproblems. It is applicable where the problem can be divided into discrete, smaller problems that are interrelated. This method saves each of the subproblem’s results and reuses them when needed, which greatly improves efficiency.
Dynamic programming and recursion both involve dividing a problem into smaller parts and solving each part just once. However, the key difference is how they store intermediate results:
Recursion: This approach relies on the system stack to keep track of subproblem results during a top-down computation. It can be inefficient because it may repeatedly solve the same subproblem many times without storing the results, leading to high computational costs, especially for problems with overlapping subproblems.
Dynamic Programming: Typically uses two main techniques: Memoization and Tabulation.
Memoization stores the results of expensive function calls and returns the cached result when the same inputs occur again. This is essentially top-down recursion with caching.
Tabulation is the typical "bottom-up" DP approach, where you solve all related subproblems first, typically by filling up an array. This often follows an iterative approach and ensures that each subproblem is only solved once.
The Fibonacci sequence is a classic example used to illustrate both recursion and dynamic programming. The Fibonacci of a number n is the sum of Fibonacci of n-1 and n-2, with base cases Fibonacci of 0 is 0 and Fibonacci of 1 is 1.
Using dynamic programming to calculate the Fibonacci sequence can be much more efficient than plain recursion, especially for large n.
Imagine we want to find the 5th Fibonacci number:
- Create an array to hold the Fibonacci numbers up to the 5th. Initially, fill it with zeros except for the first two numbers:
Fib = [0, 1, 0, 0, 0, 0]
- Fill the array using the formula (Fib[i] = Fib[i-1] + Fib[i-2]):
Fib = [0, 1, 1, 0, 0, 0]
Fib = [0, 1, 1, 2, 0, 0]
Fib = [0, 1, 1, 2, 3, 0]
Fib = [0, 1, 1, 2, 3, 5]
- Result: The 5th Fibonacci number is 5.
One classic problem that can be elegantly solved using dynamic programming is the Coin Change Problem. This problem asks for the minimum number of coins needed to make up a given amount of money using coins of specified denominations.
Problem Statement
Given:
A set of coin denominations (e.g., 1, 5, 10, 25 cents)
A total amount (e.g., 30 cents)
Find:
- The minimum number of coins required to make up the total amount.
The idea is to build up a solution using the smallest sub-problems. We create an array where the index represents amounts from 0 up to the total, and each value at an index represents the minimum number of coins required to reach that amount.
Steps to Solve:
Initialize an array
minCoinswith a size oftotal + 1. Set all values initially to a large number (infinity), except for 0, which should be 0 because zero coins are needed to make up zero amount.Iterate through each coin and update the array for each amount that can be achieved by adding that coin to a smaller amount already computed.
Initialization:
minCoins = [0, inf, inf, inf, inf, inf, inf, inf, inf, inf, inf, inf] (Amounts) 0 1 2 3 4 5 6 7 8 9 10 11Using Coin 1:
minCoins = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]Using Coin 2:
minCoins = [0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6]Using Coin 5:
minCoins = [0, 1, 1, 2, 2, 1, 2, 2, 3, 3, 2, 3]
Explanation of Steps:
Step 1: Initialize the array with infinity since initially, we do not know the minimum coins except for the 0 amount which is 0.
Step 2 and 3: For each coin, we go through all possible total amounts and update the number of coins needed if using the current coin results in fewer coins than previously recorded.
Final Result:
minCoins[11]is 3, indicating that the minimum coins needed for 11 cents using 1, 2, and 5 cents are 3 coins (for example, one 5-cent and two 2-cent coins or two 5-cent and one 1-cent).
Hopefully, this article has provided you with a clear understanding of the importance and practical applications of data structures and algorithms (DSA). Through detailed explanations and examples, including those using dynamic programming and other fundamental concepts, we've explored how mastering these elements can greatly enhance problem-solving skills and computational efficiency. Whether it's optimizing tasks, solving complex problems, or preparing for competitive programming and technical interviews, a solid foundation in DSA is indispensable. It's my sincere hope that this discussion motivates you to delve deeper into the field of data structures and algorithms.