Thread-Level Parallelism: A Focus on Cache Coherence
I am Jyotiprakash, a deeply driven computer systems engineer, software developer, teacher, and philosopher. With a decade of professional experience, I have contributed to various cutting-edge software products in network security, mobile apps, and healthcare software at renowned companies like Oracle, Yahoo, and Epic. My academic journey has taken me to prestigious institutions such as the University of Wisconsin-Madison and BITS Pilani in India, where I consistently ranked among the top of my class.
At my core, I am a computer enthusiast with a profound interest in understanding the intricacies of computer programming. My skills are not limited to application programming in Java; I have also delved deeply into computer hardware, learning about various architectures, low-level assembly programming, Linux kernel implementation, and writing device drivers. The contributions of Linus Torvalds, Ken Thompson, and Dennis Ritchie—who revolutionized the computer industry—inspire me. I believe that real contributions to computer science are made by mastering all levels of abstraction and understanding systems inside out.
In addition to my professional pursuits, I am passionate about teaching and sharing knowledge. I have spent two years as a teaching assistant at UW Madison, where I taught complex concepts in operating systems, computer graphics, and data structures to both graduate and undergraduate students. Currently, I am an assistant professor at KIIT, Bhubaneswar, where I continue to teach computer science to undergraduate and graduate students. I am also working on writing a few free books on systems programming, as I believe in freely sharing knowledge to empower others.
Thread-Level Parallelism (TLP) marks a significant shift in modern computer architecture. As advancements in uniprocessor design reached their limits in terms of instruction-level parallelism (ILP), attention turned toward more scalable methods for performance improvement. One of the primary ways to achieve higher performance is through the use of multiple processors or cores working in parallel, which can execute separate threads or tasks simultaneously. This shift is driven by several factors:
Diminishing Returns of ILP: By the early 2000s, uniprocessor performance improvements via ILP were encountering diminishing returns. The continued scaling of processor clock speeds and increases in instruction-level parallelism could no longer keep pace with performance demands. In particular, power efficiency became a critical concern, as increasing processor clock speeds led to significantly higher power consumption without proportional performance gains.
Growth of Multiprocessor Systems: In response to these challenges, multiprocessor systems became a preferred architecture for both high-end servers and general-purpose computing. These systems can handle multiple threads of execution by leveraging thread-level parallelism, where independent tasks or threads can be executed on different processors or cores simultaneously. TLP is inherently more scalable than ILP, as adding more processors can lead to linear performance improvements in the presence of sufficient thread-level parallelism.
Rise of Data-Intensive Applications: The explosion of data-intensive applications, such as those driven by internet-scale services and cloud computing, has also played a role in the shift toward multiprocessor systems. These applications require massive computational power, often in the form of parallel tasks running on multiple processors to handle large datasets and process-intensive operations.
Importance of Multicore Systems: While multiprocessor systems traditionally involved multiple chips, multicore systems—where multiple processors (cores) are embedded within a single chip—have become more prominent. Multicore processors enable parallel execution without the need for multiple physical processors, allowing for better power efficiency and performance scaling within a single die.
Shared vs. Distributed Memory Models: A critical architectural distinction in multiprocessor systems is how memory is organized and shared among the processors. In symmetric multiprocessors (SMPs), processors share a single memory space, making communication between processors relatively straightforward but imposing bandwidth limitations as the number of processors increases. In distributed shared memory (DSM) systems, memory is distributed among processors, which allows for better scaling but requires more complex communication protocols to maintain consistency across the system.
Challenges of Parallel Processing: Exploiting TLP is not without its challenges. One of the key difficulties is balancing the workloads across multiple processors and ensuring efficient communication between them. The grain size of tasks (the amount of work assigned to a single thread) plays a crucial role in determining how efficiently a system can exploit parallelism. Large-grain tasks reduce communication overhead but may limit the overall parallelism, while small-grain tasks increase parallelism but can suffer from high communication costs and synchronization delays.
Overhead of Communication: One of the most significant bottlenecks in parallel processing is the latency associated with remote memory accesses. When processors must communicate or access data located in another processor's memory, the time required for this communication can range from tens to hundreds of clock cycles, depending on the system's architecture and scale. This communication delay can severely limit the potential speedup of parallel tasks, especially in large-scale systems.
Scalability and Large-Scale Systems: As the number of processors increases, system designs must account for the scalability of both computation and communication. For example, systems designed for scientific applications often involve hundreds or thousands of processors, and specialized techniques are required to manage the communication between them efficiently. Warehouse-scale computers (WSCs) represent the extreme end of large-scale parallelism, where entire data centers are treated as a single computing resource with parallel tasks distributed across thousands of machines.
The movement from ILP to TLP has redefined modern computing, especially with the increasing prominence of multiprocessors and multicore systems. These architectures provide a more scalable path to improving performance, particularly for data-intensive and highly parallel applications. While parallelism offers significant benefits, its effective exploitation requires addressing challenges such as communication latency, task distribution, and synchronization, all of which are critical to realizing the full potential of thread-level parallelism.
Thread-Level Parallelism (TLP) is a key concept in modern computer architectures that involves exploiting parallelism across multiple processors or cores by running multiple threads simultaneously. This is especially important as the scaling of uniprocessor performance has slowed due to physical and power constraints. Multiprocessor systems, particularly those using multicore architectures, can achieve significant performance improvements by executing several threads or processes in parallel, distributing the workload across multiple processing units.
The growing demand for high-performance computing in applications like scientific simulations, cloud computing, and big data analytics has pushed the industry toward embracing TLP. By coordinating multiple threads within a single program or running several independent programs concurrently, multiprocessor systems can increase throughput and reduce overall execution time. These systems either share memory across all processors (shared-memory systems) or distribute memory among processors (distributed-memory systems), and manage parallel execution using different models of thread execution.
In shared-memory multiprocessors (SMPs), processors share a common memory space, allowing threads to communicate directly via memory. This is typically more efficient for tightly-coupled tasks where processors need frequent access to shared data. In contrast, distributed-memory systems, such as those using Distributed Shared Memory (DSM), assign separate memory to each processor. In such systems, data must be explicitly transferred between processors, which can introduce communication overhead but allows for greater scalability in large systems.
TLP is exploited in two major ways:
Parallel Processing: This involves tightly coupled threads working together on a single task. For example, a scientific computation might divide the problem into smaller subtasks, which are solved concurrently on different processors.
Request-Level Parallelism: This involves handling independent tasks or requests that can run simultaneously, such as a web server processing multiple independent client requests. This type of parallelism is common in systems that must handle many different users or tasks at the same time.
Multiprocessor systems can also be used to exploit both forms of parallelism, dynamically assigning available resources (cores or processors) to threads or processes based on workload demands.
While Instruction-Level Parallelism (ILP) focuses on parallelism within a single processor by exploiting the execution of multiple instructions simultaneously, Thread-Level Parallelism (TLP) focuses on parallelism at the thread level across multiple processors or cores. Both approaches are integral to improving the performance of modern systems, but they offer different advantages and limitations.
Instruction-Level Parallelism (ILP)
ILP is achieved through techniques such as pipelining, superscalar execution, and out-of-order execution within a single processor. These techniques enable the processor to execute multiple instructions in parallel by overlapping instruction stages (such as fetch, decode, and execute) and using multiple execution units.
Advantages:
Maximizes the performance of a single thread or process by utilizing hardware more efficiently.
Pipelining and superscalar architectures can reduce the time taken to complete individual instructions.
ILP can achieve higher performance without requiring the developer to write multi-threaded programs.
Limitations:
The level of parallelism is inherently limited by the structure of the program and the available instruction dependencies. As a result, diminishing returns are often encountered with higher degrees of ILP.
Power and energy consumption increase as more complex ILP mechanisms, such as speculative execution, are used.
ILP struggles to provide substantial performance gains in workloads with limited instruction-level concurrency.
Thread-Level Parallelism (TLP)
In contrast, TLP scales performance by distributing threads or processes across multiple processors or cores. The cores work independently, executing separate threads, thereby improving throughput.
Advantages:
Provides greater scalability than ILP, especially as the number of cores in multicore processors increases.
TLP is particularly effective for workloads that are easily parallelizable, such as scientific computing or server applications where independent requests can be handled concurrently.
More power-efficient than ILP for high-performance applications, as TLP avoids the need for complex single-core optimizations.
Limitations:
TLP requires the application to be multi-threaded or divided into independent tasks. Legacy software or applications not designed with parallelism in mind may not benefit from TLP.
Synchronization between threads can introduce overhead and limit performance gains, particularly in systems with shared resources such as memory or I/O.
The benefits of TLP depend on the architecture's ability to handle issues such as cache coherence and data consistency, which become more complex as the number of threads increases.
Ultimately, ILP focuses on exploiting fine-grained parallelism within a single processor, whereas TLP is about scaling performance across multiple processors. Both methods are often used together in modern processors—superscalar or out-of-order cores are designed to extract ILP within individual threads, while multicore processors leverage TLP to execute many threads concurrently.
With the advent of multicore processors, the landscape of processor architecture has shifted from the ILP-dominated paradigm of single-core systems to architectures that focus on TLP. Multicore processors integrate multiple processing units (cores) on a single chip, allowing these cores to share memory and resources more efficiently than multi-chip systems.
Multiprocessor architectures are systems where two or more processors work together to execute tasks concurrently. These systems are designed to exploit Thread-Level Parallelism (TLP) by distributing computational tasks across multiple processors or cores. The goal is to increase computational power and speed up task execution by breaking down workloads into smaller, parallelizable parts that can be processed simultaneously.
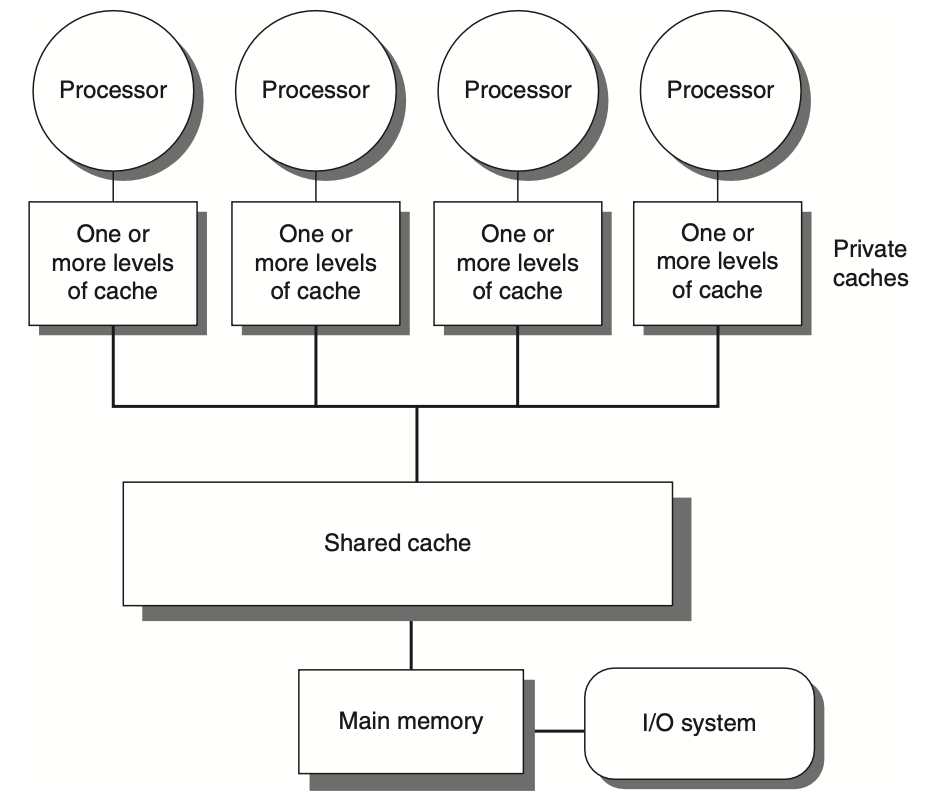
Figure: The basic structure of a centralized shared-memory multiprocessor based on a multicore chip involves multiple processor-cache subsystems sharing the same physical memory. Typically, this includes one level of shared cache, with each core also having private cache levels. The architectural advantage here is the uniform memory access time from all processors. In a multichip system, the shared cache is omitted, and processors communicate with memory over an interconnection network or bus that spans across chips, as opposed to operating within a single chip.
Multiprocessor architectures come in different configurations, typically categorized based on how processors access memory, share data, and communicate. These architectures can vary in complexity and scale, ranging from small systems with a few cores to large, distributed systems handling massive parallel computations.
There are two broad categories of multiprocessor architectures: Symmetric Multiprocessors (SMP) and Distributed Shared Memory (DSM) systems. These architectures also vary based on memory access patterns, leading to concepts like Non-Uniform Memory Access (NUMA) and distinctions between Centralized and Distributed Memory Architectures.
Symmetric Multiprocessors (SMP) are a class of multiprocessor architectures where all processors share the same memory and I/O space, and each processor has equal access to the system's resources. In an SMP system, processors operate independently but can collaborate through a shared memory space. The operating system manages tasks across processors, providing a balanced workload and ensuring that all processors are utilized efficiently.
Key Characteristics:
Shared Memory: All processors share a single memory address space. This means that every processor can directly access any part of memory, making communication between processors straightforward and efficient.
Symmetry: The term "symmetric" refers to the fact that each processor has equal access to memory and I/O devices. There is no hierarchy or preference among processors, and they can all perform the same tasks.
Single Operating System: An SMP system typically runs a single instance of an operating system that manages all the processors and their workloads. The OS schedules tasks across the available processors to ensure balanced execution.
Cache Coherence: Since all processors share the same memory space, cache coherence becomes a critical issue. Each processor may cache data locally, so it is essential to ensure that the copies of data across different caches remain consistent. This is typically handled using cache coherence protocols like MSI, MESI, or MOESI, which manage data synchronization between caches.
Advantages:
Simplicity: SMP systems are relatively simple to program compared to distributed systems because all processors access the same memory. This makes sharing data between processors easy.
Scalability: SMP systems can scale up to a reasonable number of processors, typically 2 to 32, by adding more cores to the shared memory space.
High Throughput: By enabling parallel processing, SMP systems can improve throughput for workloads that can be distributed across multiple processors.
Disadvantages:
Memory Bottlenecks: As the number of processors increases, they must compete for access to shared memory. This can lead to memory bandwidth bottlenecks, especially if multiple processors are accessing the same memory simultaneously.
Cache Coherence Overhead: Maintaining cache coherence across multiple processors becomes more challenging as the number of processors grows, leading to increased latency and communication overhead.
SMP is commonly used in multicore processors, where each core shares the same memory. For example, modern x86 processors like Intel's i7 or AMD's Ryzen use SMP principles within a single chip.
Distributed Shared Memory (DSM) is an architecture where the memory is physically distributed across multiple processors or nodes, but the system provides an abstraction of a shared memory space. Each processor has its own local memory, and data that is needed by other processors is transferred over a network. DSM provides the illusion that all processors are accessing a unified shared memory, even though the memory is distributed.
Key Characteristics:
Local Memory: Each processor or node has its own local memory, which is faster to access than remote memory.
Memory Abstraction: Although memory is physically distributed, the system provides a shared memory abstraction. This allows developers to write programs as if all processors were sharing a common memory, even though data must be transferred between processors.
Data Migration and Replication: DSM systems move or replicate data between processors as needed. When a processor accesses data that resides in another processor's memory, the data is fetched over a network and stored locally.
Consistency Models: DSM systems implement memory consistency protocols to ensure that changes to data made by one processor are visible to other processors. Depending on the implementation, these protocols can enforce strong or weak consistency guarantees.
Advantages:
Scalability: DSM systems can scale to a larger number of processors because each processor has its own local memory, reducing contention for a single memory space.
Efficient Memory Access: Processors can access local memory faster than remote memory. As a result, DSM systems can achieve better performance by minimizing remote memory access.
Flexibility: DSM can be implemented on both tightly-coupled systems (within a single machine) and loosely-coupled systems (across a network of machines), making it a flexible architecture for parallel computing.
Disadvantages:
Communication Overhead: Accessing remote memory involves communication over a network, which is slower than accessing local memory. This introduces latency and can reduce the overall performance of the system.
Complexity: Programming for DSM systems can be more complex than for SMP systems because developers must consider data locality and synchronization between processors.
DSM systems are commonly used in large-scale parallel computing environments, such as high-performance clusters and distributed computing platforms. These systems allow for efficient parallel execution of tasks across multiple nodes.
Non-Uniform Memory Access (NUMA) is a memory architecture used in multiprocessor systems where the memory access time varies depending on the memory location relative to the processor accessing it. In a NUMA system, each processor has faster access to its local memory and slower access to memory located on other processors or nodes.
NUMA is often implemented in systems that combine features of both SMP and DSM architectures. While processors share memory, access to memory is not uniform across all processors. Local memory can be accessed with lower latency, while remote memory takes longer due to inter-processor communication.
Key Characteristics:
Local and Remote Memory: Each processor has a local memory bank that it can access more quickly than memory located on other processors.
Latency Differences: Access times to memory are not uniform. Local memory access is fast, while remote memory access incurs additional latency due to communication between processors.
Scalability: NUMA systems can scale more efficiently than traditional SMP systems because processors do not compete for access to the same memory bank. By distributing memory, NUMA reduces contention and improves performance.
Advantages:
Improved Performance: By allowing processors to access local memory quickly, NUMA systems can reduce memory bottlenecks and improve performance in multi-threaded applications.
Scalability: NUMA systems scale well with increasing numbers of processors, as each processor can access its own local memory efficiently.
Disadvantages:
Programming Complexity: NUMA introduces additional complexity for developers, as they need to consider the location of data in memory. Poor data placement can result in significant performance degradation due to remote memory access.
Synchronization Overhead: Ensuring consistency between local and remote memory in NUMA systems can add overhead, particularly in systems with many processors.
NUMA is widely used in modern high-end servers, such as those running large databases or scientific simulations, where efficient memory access is critical.
Centralized Memory Architecture is a configuration where all processors in a multiprocessor system share a single, centralized memory unit. This is characteristic of traditional SMP systems. In such architectures, all processors access the same physical memory, and the memory access time is uniform across all processors. Centralized architectures are simpler to implement but can suffer from memory contention as the number of processors increases.
Characteristics of Centralized Memory Architectures:
Shared Memory: All processors share the same memory, leading to uniform access times.
Simplicity: Programming is straightforward because there is no need to manage memory locality.
Bottleneck: As more processors are added, they compete for access to the shared memory, leading to contention and reduced performance.
In contrast, Distributed Memory Architectures distribute memory across multiple processors or nodes. This is a hallmark of DSM and NUMA systems. Each processor has its own local memory, and processors communicate over a network to share data. Distributed architectures are more scalable than centralized systems, as they reduce contention for memory and allow for more processors to be added to the system.
Characteristics of Distributed Memory Architectures:
Local and Remote Memory: Processors have faster access to their local memory and slower access to remote memory located on other processors.
Scalability: Distributed architectures can scale to large numbers of processors by distributing memory across nodes, reducing contention.
Complexity: Programming for distributed memory architectures is more complex, as developers must consider memory locality and synchronization between processors.
In multiprocessor systems, where multiple processors or cores share memory, each processor often has its own cache to reduce memory access time. While caching improves performance by allowing processors to access frequently used data quickly, it introduces a major challenge: cache coherence. Cache coherence ensures that multiple caches in a system maintain a consistent view of shared data. Without it, processors may operate on stale or inconsistent data, leading to errors and incorrect program behavior.
Cache coherence refers to the property that ensures that multiple caches in a multiprocessor system maintain consistent copies of shared data. In a system with multiple caches, it is possible for each cache to hold its own local copy of a data item. If one processor modifies its local copy of the data, the change must be reflected in all other caches that hold copies of the same data. This is critical in multiprocessor systems because each processor may rely on a different version of the same data, leading to incorrect program behavior.
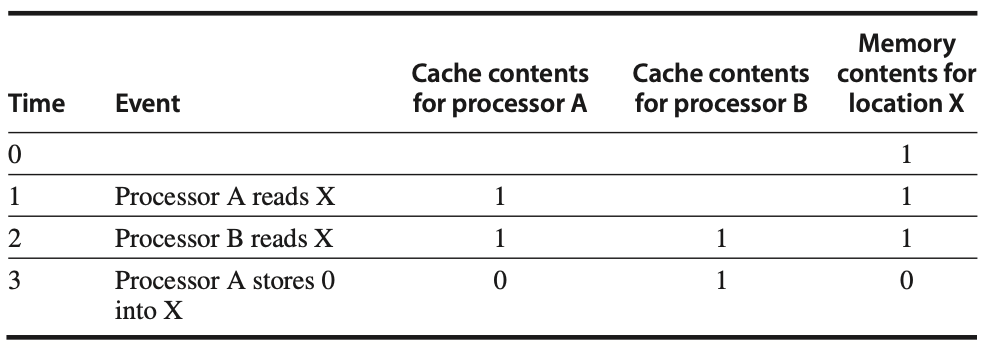
Figure: The cache coherence problem occurs when two processors, A and B, access the same memory location (X), but their caches are not synchronized. Initially, neither processor has X in its cache, and X has the value 1 in memory. After processor A writes a new value to X, A's cache and the memory are updated, but B's cache still contains the old value of 1. If processor B reads X from its cache, it will get the stale value (1), leading to inconsistency in the system. This issue exemplifies the need for cache coherence protocols to ensure that all caches reflect the most recent value of shared data.
Importance of Cache Coherence:
Correctness: Cache coherence is necessary to ensure that all processors have a consistent view of memory. Without coherence, different processors could operate on different values of the same variable, leading to incorrect computations.
Performance: Coherence protocols ensure that data is updated efficiently across multiple caches. Without these protocols, processors would have to rely on slow main memory accesses or invalid data, significantly degrading system performance.
Data Sharing: In parallel programs, processors frequently share data. Cache coherence guarantees that when one processor updates a shared data item, other processors see the change immediately or in a controlled manner. This is critical for synchronization and coordination in parallel programs.
While cache coherence ensures that all caches in a system agree on the current value of a shared data item, memory consistency governs when and how updates to memory by one processor are visible to other processors. Coherence and consistency are related but distinct concepts that together define the behavior of memory in a multiprocessor system.
Cache Coherence:
Coherence focuses on maintaining consistency for individual memory locations. A memory system is coherent if it satisfies the following two conditions:
Write Propagation: Writes made by one processor to a memory location are eventually visible to other processors. This ensures that changes to a data item are propagated across all caches that hold copies of the data.
Write Serialization: Writes to the same location are seen in the same order by all processors. This means that if two processors write different values to the same memory location, all processors must agree on the order of those writes and the final value.
Coherence deals with ensuring that all processors observe consistent values for individual memory locations, but it does not guarantee when those values become visible. For example, if Processor A writes to memory and Processor B reads from that same memory location, coherence ensures that Processor B eventually sees the updated value, but it does not specify when this will happen.
Memory Consistency:
Consistency is a broader concept that governs the order in which memory operations (reads and writes) by one processor are seen by other processors. It defines when a processor's writes to memory are visible to other processors. Unlike coherence, which deals with individual memory locations, consistency deals with the visibility of multiple memory operations across processors.
A memory consistency model specifies rules about when a write performed by one processor becomes visible to others. One common model is Sequential Consistency, where the result of execution is as if all operations (reads and writes) occurred in a single, globally agreed-upon order. This order must respect the program order on each processor.
In short, coherence ensures that individual memory locations behave correctly across processors, while consistency ensures that memory accesses (reads and writes) across the system follow a predictable order. Coherence handles the correctness of a specific memory location, while consistency governs the broader ordering of memory operations across locations.
Several issues arise when trying to maintain cache coherence in multiprocessor systems, particularly as systems scale in terms of the number of processors and the amount of shared data. These cache coherence problems can lead to significant performance degradation or incorrect program behavior if not managed properly.
1. Stale Data
One of the primary challenges in cache coherence is the presence of stale or outdated data in caches. This occurs when one processor modifies a data item, but other processors continue to operate on old versions of the same data that exist in their local caches.
Example: If Processor A writes a new value to memory, but Processor B continues to read an old version of that data from its cache, Processor B will be working with incorrect information.
Solution: Coherence protocols such as write-invalidate or write-update ensure that when a processor modifies a cache line, other processors' copies are either invalidated (forcing them to fetch a new version) or updated with the new value.
2. Write Propagation
In a multiprocessor system, when a processor writes to a memory location that is cached by other processors, the update must be propagated to all other caches. If this does not happen efficiently, processors may operate on inconsistent data.
Problem: Without proper propagation, different processors may see different values for the same memory location.
Solution: Cache coherence protocols ensure that updates made by one processor are propagated to other processors that hold cached copies of the same memory location.
3. Write Serialization
Writes to the same memory location by different processors must be serialized so that all processors see the same order of updates. Failure to enforce serialization can lead to processors reading inconsistent values, which breaks program correctness.
Example: If Processor A writes a value to a location, followed by Processor B writing a different value to the same location, all processors should agree on the order of these writes.
Solution: Coherence protocols ensure that writes to the same memory location are seen in the same order by all processors, ensuring consistent data across the system.
4. False Sharing
False sharing occurs when two processors cache different data items that reside in the same cache line. Even though the processors are working on different data, modifications to one part of the cache line cause unnecessary coherence traffic because the entire cache line is shared.
Example: If Processor A modifies one variable in a cache line, and Processor B modifies a different variable in the same cache line, both processors will invalidate each other's cache lines, even though they are not actually sharing data.
Solution: False sharing can be mitigated by careful data placement and alignment, ensuring that unrelated data does not occupy the same cache line.
5. Cache Coherence Protocol Overhead
Implementing cache coherence introduces overhead in terms of memory access latency and communication traffic between processors. Coherence protocols require processors to communicate with each other to maintain data consistency, which can slow down execution, especially in systems with a large number of processors.
- Solution: Efficient cache coherence protocols, such as directory-based coherence or snooping coherence, are designed to minimize the communication overhead and latency associated with maintaining cache coherence.
In a multiprocessor system where each processor has its own cache, maintaining a consistent view of shared data across multiple caches is crucial. Cache coherence protocols ensure that when one processor modifies a data item, the change is reflected across all caches that contain a copy of that item. These protocols must manage communication between caches efficiently to avoid performance bottlenecks and maintain correct program execution.
Cache coherence protocols typically rely on two fundamental mechanisms to ensure data consistency across multiple caches: migration and replication.
Migration: Migration refers to moving a data item from one cache to another. When a processor accesses a memory location and modifies it, the cache line containing that memory can be migrated from one cache to another, depending on which processor is using it. This eliminates the need for repeated memory accesses to fetch the same data item, thereby reducing the average access time for shared data. In other words, migration allows the data to "move" closer to the processor that is actively using it.
Replication: Replication involves creating multiple copies of a data item across different caches. If several processors need to read the same memory location, they can each hold a replicated copy of that location in their local caches. Replication improves performance by reducing the number of memory accesses for read operations. However, challenges arise when one processor modifies a replicated data item, as all other processors with copies must be updated to maintain coherence.
These two schemes—migration and replication—are the foundation of cache coherence, and cache coherence protocols leverage them to maintain consistent data across caches while minimizing memory access latency.
Cache coherence protocols can be categorized into two primary classes: directory-based protocols and snooping protocols. Each has its own approach to tracking shared data and maintaining coherence across multiple caches.
1. Directory-Based Coherence Protocols
In directory-based coherence protocols, a central directory keeps track of which processors' caches hold copies of a particular memory block. This directory can either be centralized or distributed. The directory is responsible for monitoring the state of each cache line (valid, modified, or shared) and coordinating updates between caches.
Central Directory: A central directory is located in a shared memory space, and all caches must consult it when accessing or modifying a cache line. The directory keeps a record of which caches have copies of the memory block and ensures that modifications are propagated correctly.
Distributed Directory: In larger systems, a distributed directory may be used to prevent the central directory from becoming a performance bottleneck. In this design, each memory block or cache line may have its own directory entry, distributed across the system. Each directory entry monitors the state of the memory block for a specific set of processors.
The advantage of directory-based protocols is that they scale well for larger systems because they do not require broadcasting coherence information to all caches. Instead, they only communicate with the caches that hold a copy of the shared data.
2. Snooping Coherence Protocols
In snooping-based coherence protocols, all caches monitor (or snoop) on a common communication bus. Whenever a processor modifies a data item, it broadcasts the update on the bus. Other processors "snoop" the bus to see if the memory block they have in their cache has been modified. If so, they either invalidate or update their local copy based on the specific coherence protocol.
Broadcasting: A key feature of snooping protocols is that coherence information is broadcast to all caches, ensuring that any modifications are propagated across the system. While effective for systems with a small number of processors, broadcasting can become a performance bottleneck as the number of processors increases.
Interconnect Dependency: In snooping protocols, the bus or interconnect plays a critical role in transmitting coherence information. With modern multicore processors, the interconnect between cores is often more sophisticated, using point-to-point links or rings instead of a single shared bus.
Snooping protocols work well for small to medium-sized multiprocessor systems, but they may not scale efficiently to larger systems with many processors due to the increased overhead of broadcasting coherence information.
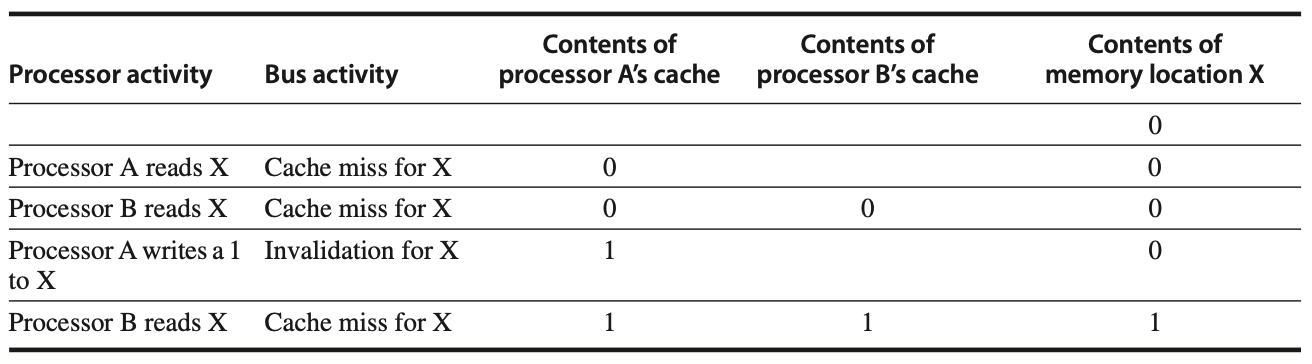
Figure: In an invalidation protocol working on a snooping bus, assume that neither cache initially holds a value for X and that the memory value of X is 0. After some processor and bus activities, processor B makes a second memory request for X, but this time, processor A responds with the updated value. This invalidates B’s original cache state, and both B’s cache and the memory content for X are updated. This approach simplifies coherence by tracking block ownership. When X is shared, ownership ensures that the processor owning the block updates other processors and memory when the block is modified. Shared caches, such as L3, help manage this across multicore systems by ensuring coherence at all levels, leading some systems to adopt directory protocols for better scalability.
To maintain cache coherence, two primary approaches are used: write-invalidate and write-update protocols. These protocols define how changes to shared data are propagated across caches.
1. Write Invalidate Protocol
In a write-invalidate protocol, when a processor wants to modify a shared data item, it invalidates the copies of that item in all other caches. Once the other caches are invalidated, only the modifying processor holds a valid copy of the data, allowing it to proceed with the write. This ensures that other processors cannot access stale data, as their cache copies have been marked invalid.
Process: The processor broadcasts an invalidate request on the bus, and all other caches check if they hold a copy of the data. If they do, they mark the cache line as invalid. The processor that issued the request can then modify its local copy of the data. When another processor needs to access the data, it will experience a cache miss and fetch the updated value from memory.
Advantages: Write-invalidate protocols reduce the amount of data transferred between caches, as only the invalidate request is broadcast. This makes them suitable for write-intensive workloads.
Disadvantages: There can be some delay when other processors try to access the invalidated data, as they must reload the updated value from memory.
2. Write Update Protocol
In a write-update protocol, instead of invalidating other caches' copies, the modifying processor updates all other caches with the new value of the data. This means that when a processor writes to a shared data item, it sends the updated value to all other caches that hold copies of that data.
Process: When a processor writes to a cache line, it broadcasts the updated value on the bus. All other processors with a cached copy of the data update their local caches with the new value. This ensures that all caches remain consistent without invalidating their copies.
Advantages: Write-update protocols keep all caches up-to-date, reducing the number of cache misses for shared data that is frequently accessed by multiple processors.
Disadvantages: Write-update protocols generate more communication traffic on the bus, as the new value must be broadcast to all caches that hold the data. This makes them less efficient for write-heavy workloads.
The basic MSI (Modified, Shared, Invalid) protocol is a simple three-state cache coherence protocol used to track the state of each cache line in a multiprocessor system. The three states are:
Modified (M): The cache line is only in this cache, has been modified, and differs from the value in main memory.
Shared (S): The cache line may be present in other caches and matches the value in main memory.
Invalid (I): The cache line is not valid and must be fetched from memory or another cache before it can be used.
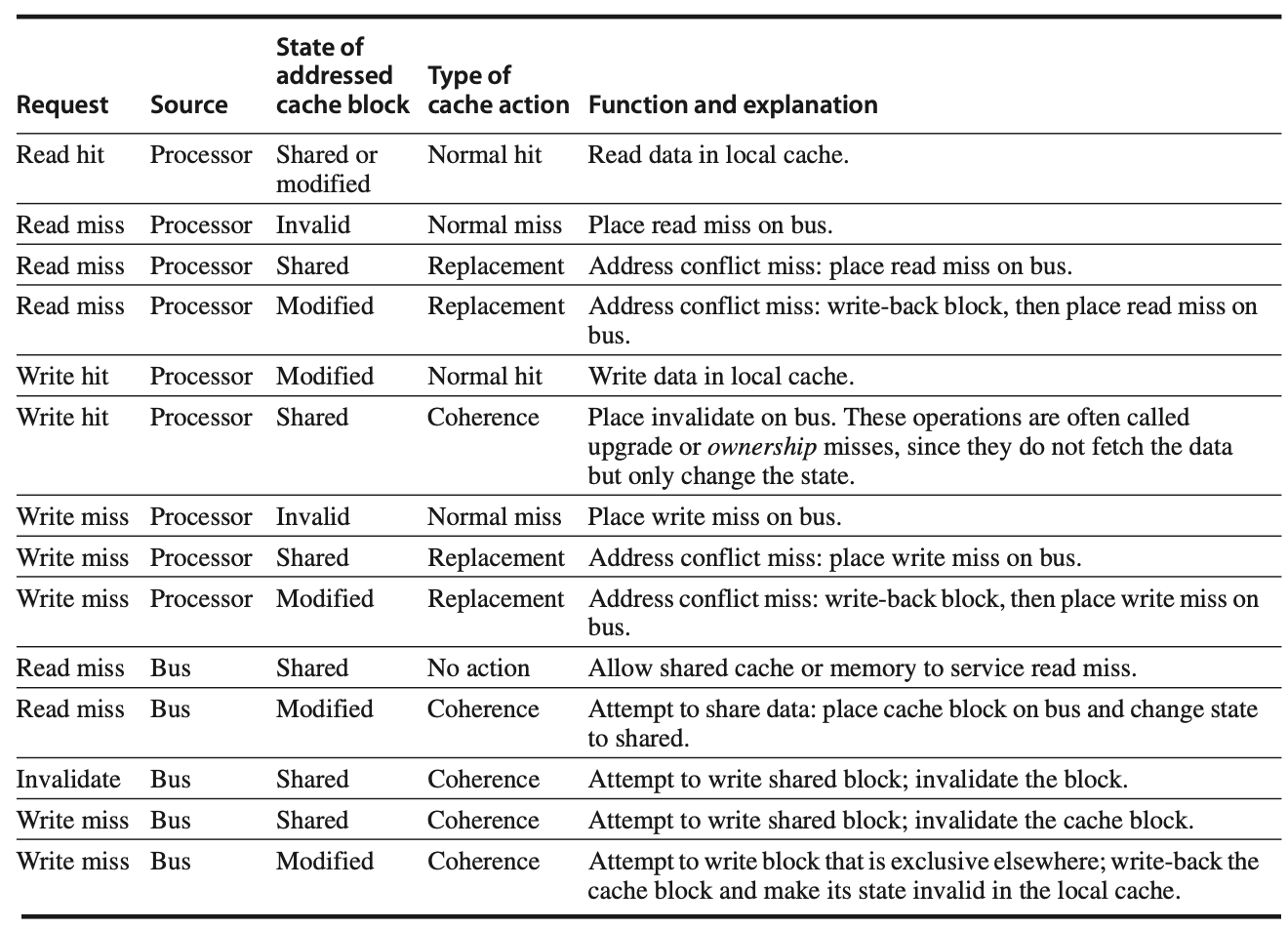
Figure: The cache coherence mechanism handles requests coming from both the processor core and the shared bus. It determines whether the request results in a hit or miss within the local cache and evaluates the state of the cache block involved in the request. There are different types of actions the cache can take, such as a normal action (similar to what a uniprocessor would perform), a replacement action (like a cache replacement miss in a uniprocessor), or a coherence action, which is necessary to maintain consistency across multiple caches. Depending on the state of the cache block in other caches, the coherence mechanism might trigger an action. For coherence-related requests such as read or write misses or invalidations detected on the bus, actions will only be initiated if the address matches a valid block in the local cache. The process ensures that the cached data remains consistent across multiple processors.
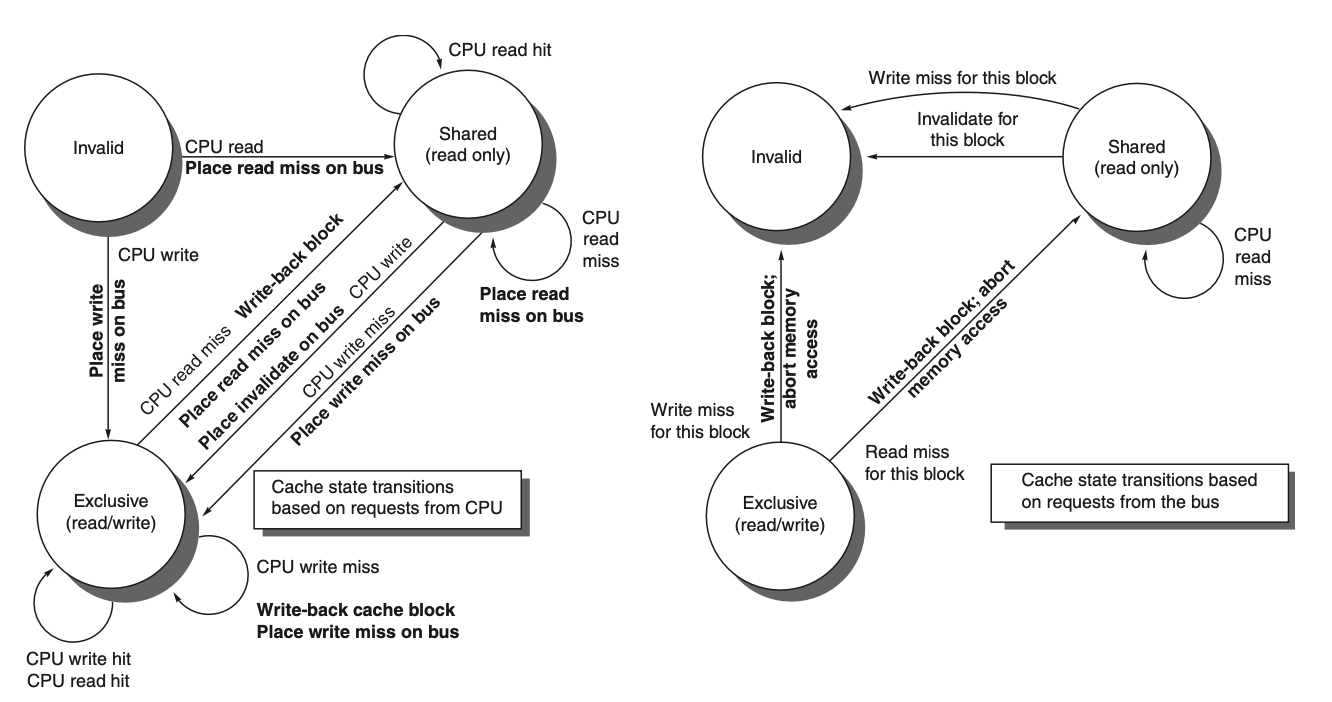
Figure: The figure describes the write-invalidate cache coherence protocol for a private write-back cache, detailing the state transitions for each block in the cache. The cache states are depicted in circles, and any transition is triggered by a stimulus, such as a read or write miss, which causes a state change. The left side of the diagram focuses on transitions caused by the local processor, while the right side represents transitions triggered by bus operations. For instance, a read miss to a block in the shared state does not target the same address, making it a cache miss, while a write miss to a block in the exclusive state happens when the requested address isn't found in the local cache. These events trigger cache replacement or invalidate actions. The protocol assumes that in case of a read miss for a block that is clean across all caches, memory or a shared cache will provide the required data. In practice, additional complexities, such as handling exclusive unmodified states, are part of the invalidate protocols. In a multicore system, this typically involves coordination between the private caches (e.g., L1) and the shared cache (usually L3 or L2), connected by a bus that ultimately interfaces with memory.
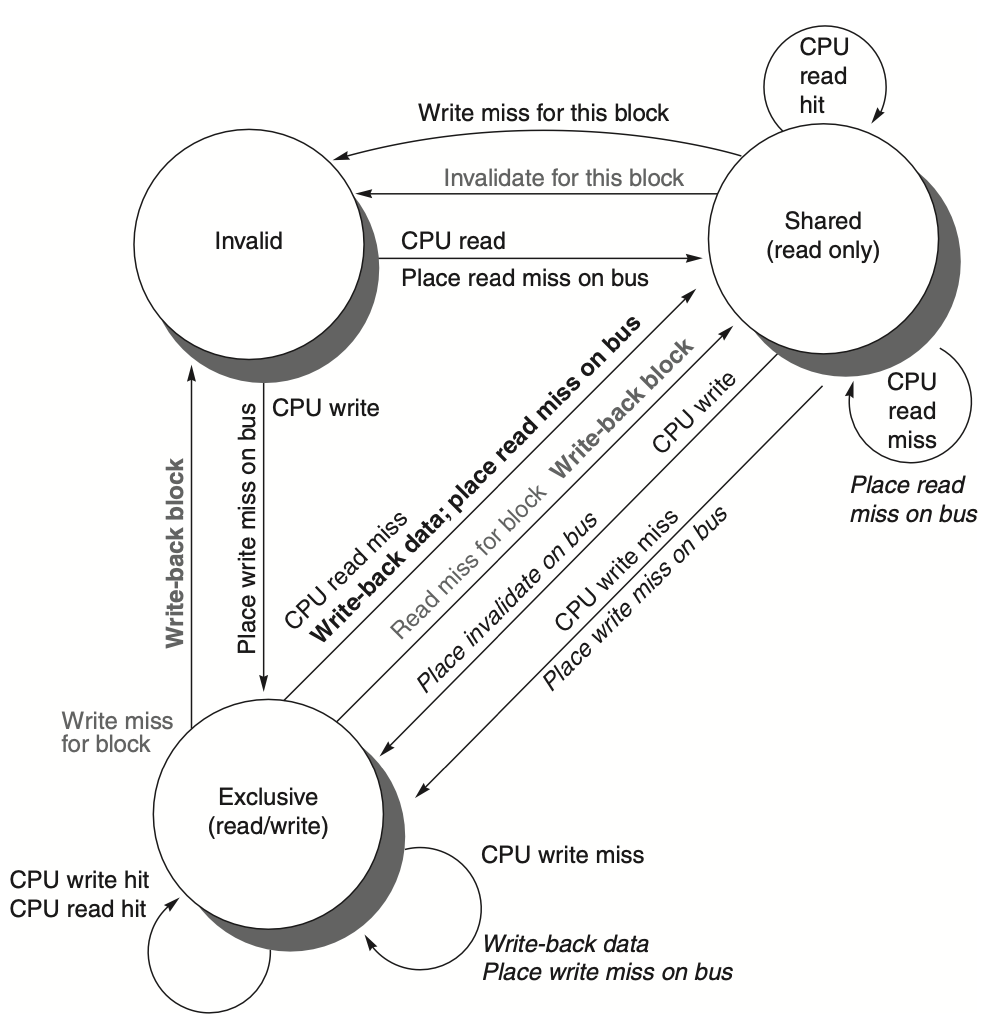
Figure: It presents a cache coherence state diagram where transitions in the state of a cache block are caused either by the local processor's actions, shown in black, or by activities on the shared bus, shown in gray. Just like in the previous figure, the key actions or events triggering these transitions are emphasized in bold, demonstrating the changes in state based on whether the processor or the bus initiates the request. The diagram highlights the dual responsibility of cache coherence management, where both local and external (bus) activities can influence the coherence state of a cache block.
Two common extensions to the MSI protocol are MESI and MOESI, which add additional states to optimize performance.
1. MESI Protocol (Modified, Exclusive, Shared, Invalid)
The MESI protocol adds an Exclusive (E) state to the basic MSI protocol. The exclusive state indicates that a cache line is present in only one cache but has not been modified.
Exclusive (E): The cache line is present in only one cache and matches the value in main memory. Since the line is not shared, it can be modified without broadcasting an invalidate message.
The MESI protocol improves performance by reducing the need for invalidation messages. If a cache line is in the exclusive state, it can be modified without informing other caches since no other caches hold a copy of the data.
2. MOESI Protocol (Modified, Owned, Exclusive, Shared, Invalid)
The MOESI protocol builds on MESI by adding an Owned (O) state, which indicates that a cache holds a modified copy of the data, but the main memory is not up-to-date.
- Owned (O): The cache line is held in a modified state, but other caches may have copies of the data in the shared state. The owned cache is responsible for supplying the data to other caches and memory when needed.
The MOESI protocol improves efficiency by allowing caches to share data without immediately updating main memory. If a cache line is in the owned state, it can supply the data to other caches without writing back to memory, reducing memory bandwidth usage.
The Exclusive and Owned states introduced in MESI and MOESI allow for finer control of cache coherence, reducing unnecessary communication and improving overall performance.
Exclusive: The exclusive state allows a processor to modify data without broadcasting invalidation messages, as it is the sole owner of the data. This reduces coherence traffic for data that is only used by one processor.
Owned: The owned state allows modified data to be shared between caches without immediately writing it back to memory. This reduces memory bandwidth usage by deferring write-backs and allowing caches to directly share modified data.
Symmetric shared-memory multiprocessors (SMPs) are a widely-used architecture in which multiple processors share the same memory. Each processor in an SMP has equal access to memory, and they communicate through a shared bus. While this architecture has advantages in terms of ease of programming and efficiency, it also faces several limitations, especially when scaling to larger systems.
1. Scalability Challenges with Shared-Memory Systems
One of the primary challenges with symmetric shared-memory multiprocessors is scalability. In an SMP system, as the number of processors increases, each processor must compete for access to the shared memory and the communication bus. This contention for shared resources can lead to bottlenecks, especially when multiple processors try to access the same memory address or the shared bus at the same time.
Bus Contention: As more processors are added to the system, the shared bus becomes a point of contention. Each processor must wait for its turn to access the bus, and this waiting time grows as the number of processors increases. For smaller systems, this contention may not be significant, but in larger systems, it can severely limit performance.
Memory Bandwidth: The shared memory must service requests from multiple processors simultaneously. As the number of processors increases, the memory bandwidth becomes a limiting factor, as it cannot provide sufficient data to all processors simultaneously. This results in memory bottlenecks that hinder the scalability of SMP systems.
Cache Coherence Overhead: In SMP systems, maintaining cache coherence becomes increasingly complex as more processors are added. The protocols used to maintain coherence, such as snooping, must handle a larger number of caches, which increases the communication overhead. The coherence protocol must ensure that all caches have a consistent view of memory, but this requires significant communication between processors, especially as the system grows larger.
2. Bandwidth Limits for Snooping Protocols
Snooping protocols are a common method for maintaining cache coherence in SMP systems. In these protocols, all caches "snoop" on the bus to detect changes to memory made by other processors. While snooping is effective for small to medium-sized systems, it faces significant limitations as the system grows.
Bus Bandwidth Saturation: Snooping relies on broadcasting memory accesses over a shared bus. As the number of processors increases, the number of memory accesses also increases, which places a heavy load on the bus. The bus bandwidth can become saturated, meaning that it cannot accommodate any more traffic, leading to delays and reduced performance.
Latency Due to Snooping: Each cache must continuously monitor the bus to ensure that it has the most up-to-date version of any data. This snooping process adds latency, especially in systems with a large number of processors. When a processor writes to a memory location, the invalidation or update messages must be broadcast to all other caches, and this communication overhead grows with the number of processors.
Scalability Issues: The bandwidth limitations of snooping protocols make them unsuitable for systems with a large number of processors. As the number of processors increases, the bus becomes overwhelmed with coherence messages, and the system's performance degrades. For large-scale multiprocessors, alternative coherence mechanisms, such as directory-based protocols, are more effective.
Implementing snooping cache coherence involves several challenges, particularly related to ensuring that coherence operations are atomic and managing bus arbitration. In snooping-based systems, all caches monitor the bus for memory transactions, and they must ensure that any changes to shared data are propagated correctly to maintain coherence.
1. Challenges of Implementing Atomic Coherence Operations
An atomic operation is one that is executed entirely without interruption, ensuring that no other operations can occur in the middle of it. In snooping protocols, ensuring that coherence operations are atomic is critical, as two processors might attempt to modify the same memory location at the same time.
Non-atomic Actions: In reality, most coherence operations in modern multiprocessors are not atomic. For example, when a processor detects a cache miss in its local cache (L2 or L3), it must arbitrate for access to the shared bus before sending an invalidation or update message. During this arbitration process, other processors might attempt to modify the same memory location, creating the possibility of race conditions.
Deadlocks and Race Conditions: Non-atomic coherence operations can lead to deadlocks, where multiple processors wait indefinitely for access to the bus or memory. Similarly, race conditions can occur when two processors try to modify the same data at the same time, leading to inconsistent data in caches. To prevent these issues, coherence protocols must ensure that only one processor can modify a cache line at a time.
Handling Misses Atomically: When a processor experiences a cache miss, it must communicate with other processors to retrieve the latest version of the data. This requires several steps, including broadcasting a read miss request, receiving invalidation messages from other caches, and loading the updated data into the local cache. These steps must be coordinated carefully to avoid race conditions, but they are not atomic in most systems, leading to complexity in the implementation.
2. Bus Arbitration and Cache Misses
Bus arbitration is the process by which multiple processors compete for access to the shared communication bus. In a multiprocessor system, the bus is a critical resource, as all memory accesses and coherence messages must be transmitted over it. Bus arbitration becomes particularly important in snooping protocols, where multiple processors might simultaneously attempt to modify the same memory location.
Arbitrating for the Bus: In a snooping protocol, when a processor wants to modify a shared cache line, it must first gain access to the shared bus. Bus arbitration ensures that only one processor can access the bus at a time, preventing multiple processors from broadcasting conflicting coherence messages simultaneously. Various arbitration mechanisms, such as priority-based or round-robin arbitration, are used to determine which processor gets access to the bus.
Handling Cache Misses: When a cache miss occurs, the processor must retrieve the data from another cache or memory. In snooping systems, the processor broadcasts a read miss message on the bus, and other caches check if they have the requested data. If a cache holds the data, it sends the data to the requesting processor, completing the coherence transaction.
Cache misses can be particularly challenging in large systems, where many processors may experience misses simultaneously. The bus can become a bottleneck, as each miss requires arbitration and broadcast messages. This can lead to delays, especially if multiple processors are competing for access to the same data.
Serializing Writes: In snooping protocols, write operations must be serialized to ensure consistency. When a processor wants to modify a cache line, it must invalidate copies of the data in other caches. This invalidation process requires access to the bus, and it must be completed before any other processor can modify the same data. Bus arbitration ensures that write operations are serialized, but this can create delays if many processors are trying to write to shared data simultaneously.
Snooping-based coherence is a straightforward and widely implemented approach, especially in smaller-scale multiprocessors. In this scheme, each cache that holds a copy of a memory block "snoops" on a shared broadcast medium (typically a bus). Whenever a processor performs a read or write operation on a shared block, it broadcasts this operation on the bus. All other caches with a copy of the block listen (snoop) and either invalidate or update their copy, ensuring coherence.
Advantages:
Simple to implement: The snooping protocol is relatively easy to implement in smaller systems where all processors are connected via a shared bus. Each cache simply listens for updates on the bus and adjusts its state accordingly.
Low latency: Since all caches are connected to the same bus, snooping ensures that updates propagate quickly across caches. This immediacy minimizes the time between when a data modification occurs and when other caches are updated.
Broadcasting: Every cache can see all memory transactions, making it easy to enforce coherence without complex structures.
Challenges:
Scalability: The main drawback of snooping-based schemes is their poor scalability. As the number of processors grows, the shared bus becomes a bottleneck. Multiple processors generating coherence traffic can saturate the bus, leading to high contention and reduced performance.
Bandwidth consumption: Every cache miss or write-back generates broadcast traffic, and every cache has to snoop all messages. This can significantly increase the bandwidth demands on the bus, particularly as system size grows.
Coherence traffic: Since every memory transaction is broadcast, even caches that do not hold a copy of the relevant block must process the broadcast message. This inefficiency becomes more pronounced in large-scale systems with numerous caches.
As the number of processors in a system increases, the demands on the memory subsystem grow exponentially. In a multiprocessor system with a high clock speed (e.g., a 4 GHz clock) and multiple cores (e.g., four cores per chip), the system may require several gigabytes of memory bandwidth per second to maintain coherence. For example, a system may require as much as 170 GB/sec of bus bandwidth for coherence traffic alone, which can quickly outstrip the capability of any bus-based snooping system.
Bandwidth issues:
Coherence traffic: As snooping-based coherence systems scale up, the majority of the bus bandwidth is consumed by coherence traffic (i.e., broadcasts to maintain consistency), rather than useful memory accesses.
Saturation: The bus is easily saturated as the number of processors grows, and snooping every cache on every memory transaction becomes infeasible.
Alternatives to bus-based designs: In large multiprocessor systems, interconnection networks (such as crossbars or point-to-point links) are used instead of shared buses to improve bandwidth and scalability.
Scalability limitations:
Bus contention: Snooping protocols are limited by the shared bus. When too many processors are present, the overhead of snooping all cache misses and invalidations overwhelms the bus, causing delays and reducing system throughput.
Cache coherence traffic overhead: In larger systems, coherence traffic dominates, and the bus no longer serves as an efficient medium for communication.
To address the scalability and bandwidth challenges of snooping-based schemes, directory-based protocols are commonly used in larger multiprocessor systems. In a directory protocol, a directory keeps track of which caches have copies of a given memory block. Instead of broadcasting every memory transaction, the directory acts as a centralized manager that sends targeted coherence messages to only those caches that hold copies of the relevant data.
Key benefits of directory protocols:
Reduced traffic: Directory-based protocols drastically reduce coherence traffic by eliminating the need for broadcasts. Only the relevant caches are notified when a block is read or written, leading to lower bandwidth demands.
Scalability: Since the directory eliminates the need for a shared bus, it scales much better to larger systems. The directory can be distributed across multiple nodes, ensuring that the coherence protocol can handle hundreds or thousands of processors.
Less contention: Unlike snooping, where all caches compete for access to the bus, directory protocols avoid such contention by directing messages only to the caches that need to update or invalidate their copies.
Challenges:
Directory storage overhead: One of the main challenges of directory-based protocols is that the directory must store information about every memory block and which caches hold a copy of it. This requires significant storage overhead, especially in systems with large memory spaces.
Latency: Directory protocols can introduce additional latency, as a processor must first consult the directory before it can proceed with reading or writing a memory block.
To further improve scalability, distributed directory protocols are used in large-scale multiprocessor systems. In a distributed directory, the directory information for memory blocks is spread across multiple processors or memory nodes, rather than being centralized in one location. This reduces the bottleneck of a single directory and allows the coherence protocol to scale to larger systems.
Key characteristics:
Distribution of directory entries: In a distributed directory protocol, the directory entries for a given memory block are stored at the memory node that owns the block. This eliminates the need for a central directory, spreading the coherence load across the system.
Directory operations: When a processor needs to read or write a memory block, it sends a message to the directory entry at the memory node that holds the block. The directory then coordinates the necessary coherence actions (e.g., invalidating other copies, granting exclusive access, etc.).
Scalability: Distributed directories are highly scalable because each directory entry is managed independently, reducing the contention that would otherwise occur in a centralized system.
In directory-based protocols, the directory must keep track of which processors have cached copies of each memory block. This is often done using bit vectors, where each bit in the vector corresponds to a processor or cache.
Key points about bit vectors:
Tracking ownership: The bit vector indicates whether a particular cache holds a copy of a memory block. For example, if the system has 64 caches, the bit vector will have 64 bits, and each bit will be set or cleared depending on whether that cache has a copy of the block.
Efficient tracking: By using bit vectors, the directory can efficiently track multiple caches that share a block without needing complex data structures. This helps reduce the overhead associated with managing coherence information.
Invalidation and updates: When a processor writes to a block, the directory consults the bit vector to determine which caches need to be sent invalidation or update messages.
Directory-based cache coherence protocols are designed to ensure consistency across caches in distributed shared-memory multiprocessor systems, offering a scalable alternative to snooping-based protocols. In directory-based systems, a directory keeps track of which caches store copies of a memory block, ensuring that coherence is maintained without broadcasting every memory transaction.
In directory-based protocols, the directory coordinates several key operations involving memory blocks. Each operation must ensure that caches receive the most recent data or invalidate stale copies. The three fundamental operations are:
Read Miss: Occurs when a processor attempts to read a memory block that is not present in its cache. The directory looks up the state of the block and sends the data from memory (or from another cache that holds the most recent copy) to the requesting processor. If the block is shared by multiple caches, it transitions to the "Shared" state.
Write Miss: A write miss happens when a processor tries to write to a block that is either uncached or held by other processors. The directory must invalidate all shared copies of the block in other caches, granting exclusive access to the requesting processor. The block's state is updated to "Exclusive" or "Modified," indicating that only one cache has a valid copy.
Data Write-Back: If a cache holding a modified block evicts the block, it must write the updated data back to the memory. The directory is informed, and the block transitions to "Uncached" in the directory, clearing its tracking of which caches have copies.
Each cache block in a directory-based protocol can exist in one of several states, which determine how the directory manages coherence:
Shared: Multiple caches hold copies of the block, and the value in memory is up to date. All caches with the block are allowed to read but not write it.
Uncached: No cache has a copy of the block. The value of the block is only stored in memory, and it is not present in any cache.
Modified: Only one cache has a copy of the block, and it has been written to. The value in memory is now out of date, so the cache that holds the modified block is responsible for providing the most recent version.
Directory protocols typically use bit vectors to track which caches hold copies of a given memory block. Each bit in the vector corresponds to a specific cache or processor core. If a cache holds a copy of the block, the corresponding bit is set to 1; otherwise, it is set to 0.
Efficient Tracking: Bit vectors allow the directory to efficiently manage multiple caches, ensuring that it only communicates with those caches that hold a copy of the block.
Coherence Messages: When a processor requests a block or performs a write operation, the directory consults the bit vector to identify which caches need to be updated or invalidated.
In directory-based systems, cache blocks transition between states based on read and write operations. The following state transitions are common:
Read Miss (Uncached → Shared): When a cache requests a block that is currently uncached, the directory sends the block to the requesting cache and transitions the block to the "Shared" state.
Write Miss (Shared → Modified): If a cache wants to write to a block that is currently in the "Shared" state, the directory must invalidate the block in all other caches and transition the block to the "Modified" state in the requesting cache.
Write Back (Modified → Uncached): If a cache holding a modified block evicts the block, it writes the block back to memory, and the directory marks the block as "Uncached."
These transitions ensure that only one cache can modify a block at a time, while allowing multiple caches to read a block simultaneously.
In directory protocols, read and write misses trigger specific interactions between the directory and the caches. For example:
Read Miss: The requesting node sends a read miss message to the directory. The directory responds by providing the requested data from memory or from another cache. If other caches have the block, the directory marks the block as "Shared" and updates its bit vector to track which caches have copies.
Write Miss: The requesting node sends a write miss message to the directory. The directory responds by invalidating the block in all other caches, granting exclusive write access to the requesting node. The block's state is updated to "Modified."
The key cache block states in directory-based coherence are Shared, Exclusive, and Modified, with each state dictating the behavior of the directory:
Shared: Multiple caches can hold a read-only copy of the block.
Exclusive: Only one cache holds a writable copy, but the block is not modified.
Modified: Only one cache holds the block, and it has been written to. The directory tracks the cache that holds the block, and memory may be out of date.
In directory-based coherence, the memory and cache directories work together to manage block states and coherence actions. The directory tracks the state of each memory block and coordinates communication between caches.
Local Node: A cache that holds a block is a local node. The local node interacts with the directory for read or write misses.
Home Node: The home node is the memory location that stores the block when it is not cached. The home node's directory tracks the state of the block and manages coherence actions.
Remote Node: If a cache holds a copy of a block that originated in another node, it is a remote node. The directory must send coherence messages to remote nodes to ensure they update or invalidate their copies.
In directory-based protocols, ownership of a cache block is crucial for maintaining consistency. Ownership determines which cache is responsible for supplying the most recent data and managing coherence.
Exclusive Ownership: When a cache writes to a block, it gains exclusive ownership. The directory updates its records to reflect that only this cache has the valid copy.
Shared Ownership: If a block is shared among multiple caches, the directory must track all caches that hold the block.
Invalidations: When a cache writes to a block, the directory sends invalidation messages to all other caches holding the block, ensuring that only the writing cache has the valid data.
In distributed memory systems, managing cache block ownership becomes more complex. The directory must keep track of which node owns the most recent copy of the block.
Home Directory: The home directory keeps track of block ownership. When a block is modified, the home directory is responsible for coordinating invalidation messages and transferring ownership to the modifying cache.
Remote Ownership: In some cases, a remote node may become the new owner of a cache block after modifying it. The directory tracks the remote owner and coordinates coherence actions accordingly.
The memory directory plays a central role in maintaining coherence:
Invalidation Messages: When a cache writes to a block, the directory sends invalidation messages to other caches holding the block. This ensures that the writing cache has exclusive access to the data.
Tracking Cache Blocks: The directory maintains a record of which caches hold a copy of each block, using bit vectors to track this information.
Directory-based protocols introduce storage overhead due to the need to track the state of each memory block and which caches hold copies. Several optimization techniques are used to minimize this overhead:
Sparse Directories: Instead of maintaining full bit vectors for all blocks, some systems use sparse directories that only track frequently accessed blocks. This reduces the storage overhead at the cost of slightly increased complexity.
Hierarchical Directories: In large systems, directories may be organized hierarchically to reduce the storage and communication overhead. Each level of the hierarchy tracks blocks at different granularity, reducing the amount of data each directory must store.
Coarser Cache Blocks: By tracking larger cache blocks (e.g., multiple memory words in a single block), the directory can reduce the number of entries it needs to maintain.
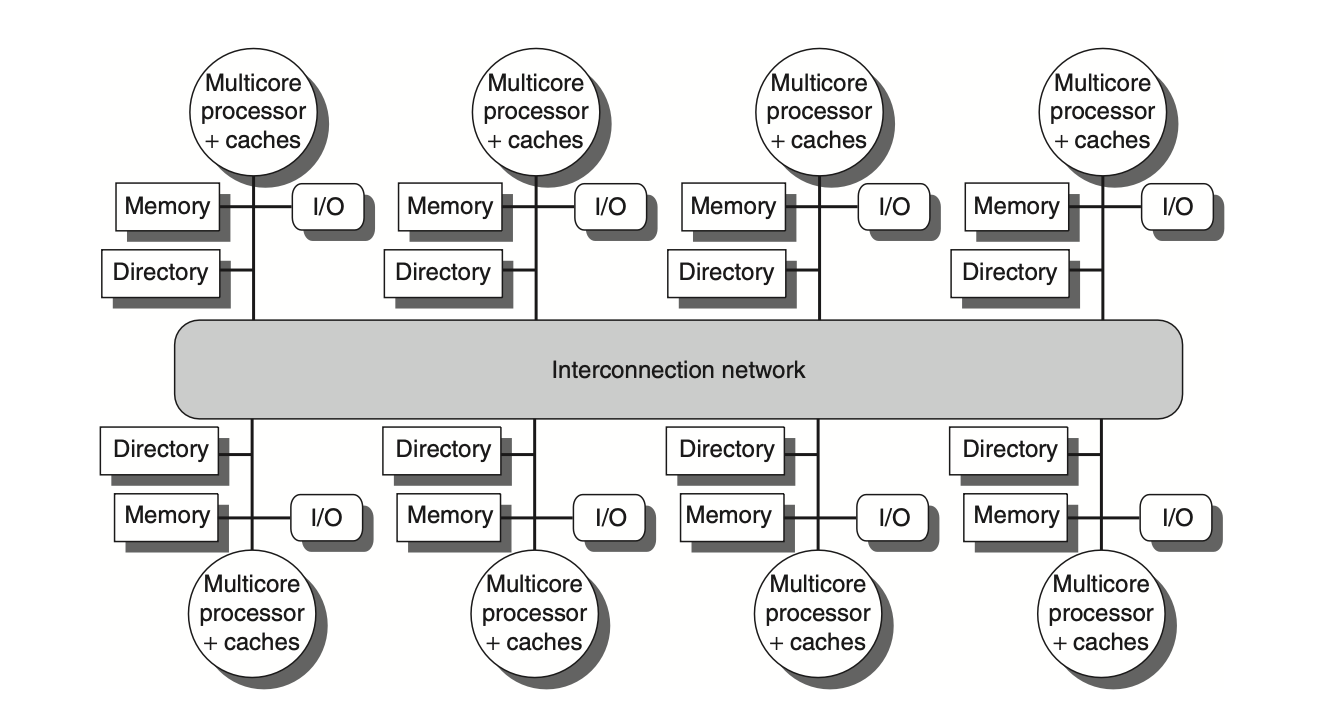
Figure: In a distributed-memory multiprocessor system, a directory is added to each node to manage cache coherence. The node, in this context, typically refers to a multicore chip. The directory's role is to track which caches are sharing specific memory addresses associated with that node. This directory may be located either within or outside the multicore chip. The coherence mechanism ensures that the directory maintains updated information about the memory and handles any actions required to maintain consistency across caches within the multicore node.
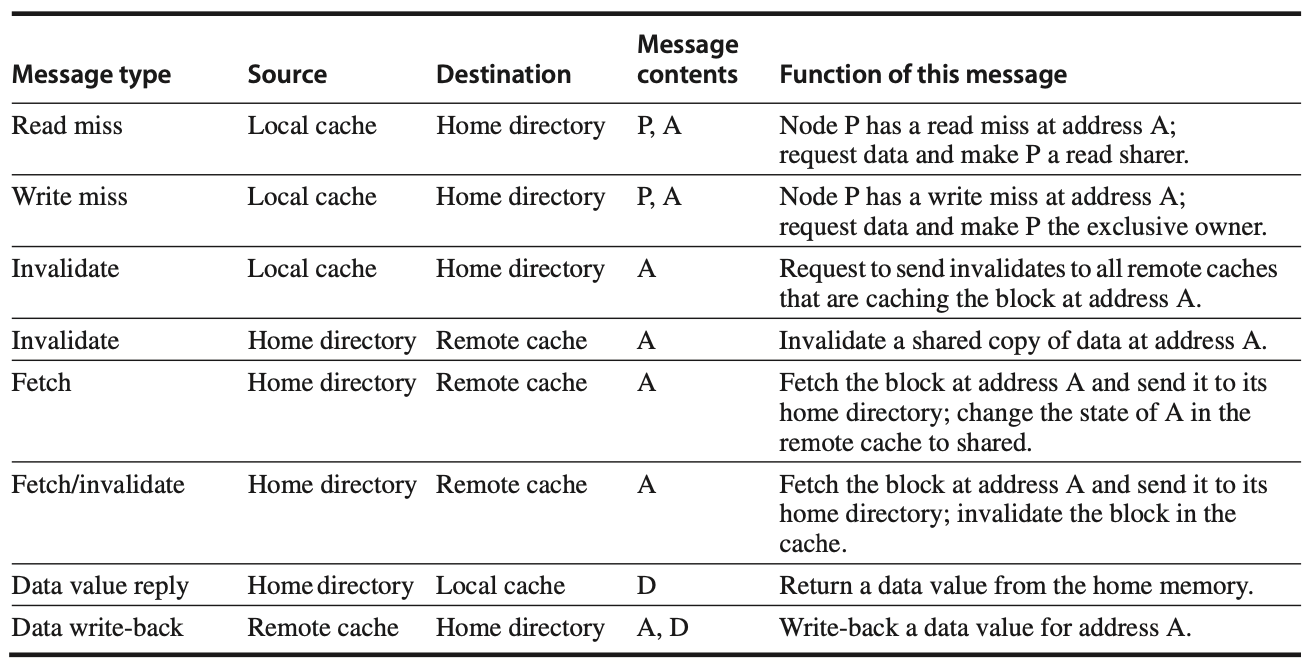
Figure:In a directory-based cache coherence system, nodes communicate through specific messages to ensure consistency across caches. Requests are sent from the local node to the home node, typically asking for data in case of a read or write miss or to invalidate copies held by other nodes. The home node, in turn, may send messages to remote nodes to retrieve or invalidate the necessary data, and then sends the data back to the requesting node in response to the miss. Additionally, when cache blocks are evicted, or when specific fetch or invalidate requests are processed, the data is written back to the home memory to maintain an updated and consistent state. This write-back process simplifies the coherence protocol by ensuring that any modified cache blocks are saved back to memory, keeping shared blocks accurate and reducing the complexity of state management.
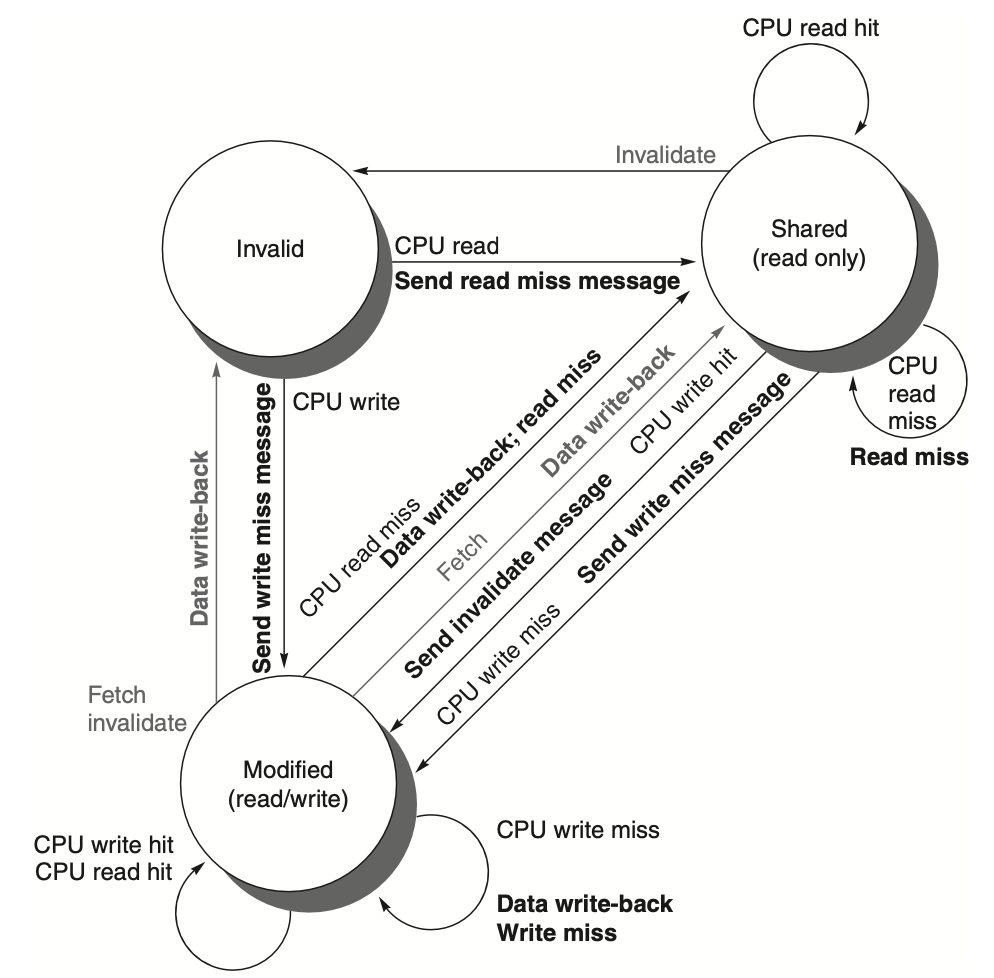
Figure: In a directory-based system, the state transitions for cache blocks operate similarly to those in a snooping system, but with some key differences. Instead of broadcasting write misses across the bus, the system uses explicit invalidate and write-back requests to handle coherence. Local processor requests trigger state transitions, while actions from the home directory handle the communication between nodes. When a processor attempts to write to a shared cache block, this is treated as a miss, though the system can grant ownership or perform an upgrade request without necessarily fetching the block itself. This approach allows more efficient management of cache coherence by reducing unnecessary block transfers.
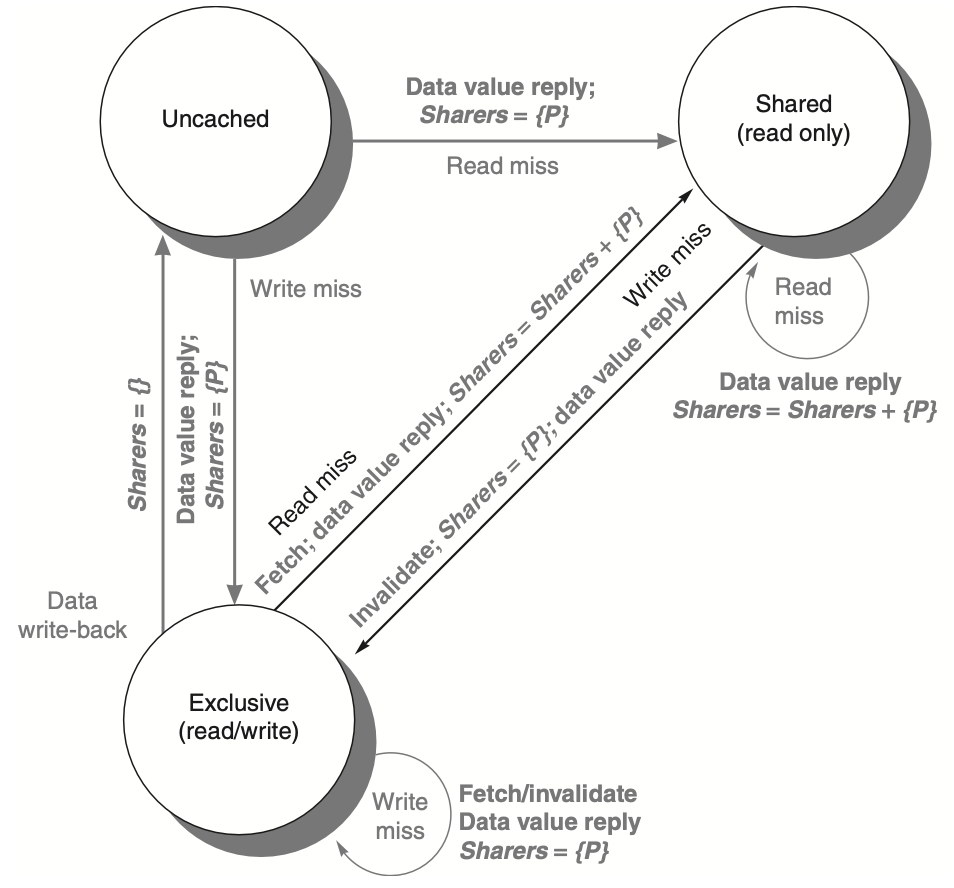
Figure: The state transition diagram for a directory in a distributed-memory system mirrors the structure and states found in the transition diagram of an individual cache block. However, in the case of the directory, all actions are triggered externally, which are represented in gray in the diagram. The bold parts of the diagram indicate the specific actions taken by the directory in response to these external requests, emphasizing its role in managing cache coherence by coordinating interactions between nodes.
Problems
- You are designing a shared-memory multiprocessor system with 8 cores, each core having its own private L1 cache. The system uses the MESI cache coherence protocol. Suppose Core 1 modifies a shared variable that is also being read by Core 3. Explain, step-by-step, how the MESI protocol ensures cache coherence between Core 1 and Core 3. Additionally, what will happen if Core 2 tries to write to the same variable immediately after Core 1’s modification?
Solution: In the MESI protocol, the cache line can be in four states: Modified (M), Exclusive (E), Shared (S), or Invalid (I). Initially, when Core 1 modifies the shared variable, it must invalidate any copies of that variable in other cores' caches. This is done by sending an invalidation message to the other caches. Core 3’s copy of the shared variable, which was in the Shared state, becomes Invalid. When Core 3 attempts to read the variable again, it will result in a cache miss, and Core 3 will fetch the updated value from memory (or directly from Core 1, if the system supports cache-to-cache transfers). If Core 2 tries to write to the variable after Core 1’s modification, it must first invalidate Core 1’s copy (which is in the Modified state), and then take ownership of the cache line to write the new value.
- In a distributed shared-memory (DSM) system with 4 processors, each processor has its own private memory. Data from other processors can be accessed through explicit communication between them. Explain how false sharing could occur in this system when processors access different variables residing in the same cache line. Provide a scenario where this causes performance degradation, and suggest a way to mitigate the issue.
Solution: False sharing occurs when processors access different variables that happen to be located on the same cache line. In a DSM system, if Processor 1 updates a variable x in a cache line, and Processor 2 reads a different variable y in the same cache line, Processor 2’s cache may invalidate the entire line due to coherence protocol rules, even though y wasn’t modified. This causes unnecessary cache invalidations and coherence traffic, leading to performance degradation. For example, if two threads frequently modify variables in the same cache line, false sharing will result in repeated cache invalidations and reloads. To mitigate this, padding can be used to separate variables into different cache lines, ensuring that each variable occupies its own line and reducing false sharing.
- Consider a symmetric multiprocessor (SMP) system with 16 cores and a unified L3 cache shared by all cores. The L3 cache uses a write-invalidate protocol to maintain coherence. Core 5 writes to a memory location, and Core 10 reads the same memory location immediately afterward. Explain the sequence of events in maintaining cache coherence. Now, consider Core 8 wants to write to that same memory location. How does the write-invalidate protocol handle this?
Solution: When Core 5 writes to the memory location, the write-invalidate protocol invalidates the copies of the cache line in other cores (such as Core 10 and Core 8). If Core 10 tries to read the memory location, it will experience a cache miss and fetch the updated value from Core 5 (if the system supports cache-to-cache transfers) or from the main memory. When Core 8 wants to write to the same memory location, it will first send an invalidation request to other cores holding the cache line. After invalidating their copies, Core 8 will take ownership of the cache line, update it, and mark it as Modified in its cache.
- In a NUMA (Non-Uniform Memory Access) system, each processor has local memory, and memory access times vary based on whether the data is in local or remote memory. Suppose you are tasked with optimizing a multi-threaded application running on this NUMA system. Explain how data placement and thread placement strategies can be used to minimize memory access latency. Illustrate your explanation with an example of a task where improper data placement leads to significant performance degradation.
Solution: In a NUMA system, accessing local memory is faster than accessing remote memory. To optimize performance, data and threads should be placed in memory close to the processors that are executing the corresponding tasks. This is often achieved through first-touch memory allocation, where data is allocated on the memory bank of the processor that first accesses it. If threads are improperly placed, accessing remote memory can lead to high latencies. For example, if Thread A on Processor 1 frequently accesses data stored in Processor 2's memory, performance will degrade due to repeated remote memory accesses. The solution is to place the data close to the processor that will access it most frequently, ensuring that threads operate on local memory as much as possible.
- You are working on a scientific simulation that involves a large number of parallel tasks. The system is a 32-core multicore processor with cache coherence managed by the MOESI protocol. Describe a situation in which multiple cores need to frequently update shared data. Explain how the MOESI protocol manages coherence in this situation, and what impact this has on the memory consistency of the system. What optimization techniques could be applied to reduce coherence traffic and improve performance?
Solution: In the MOESI protocol, cores can share and modify data efficiently. For example, Core 1 could modify a shared variable, changing its cache line state to Modified, while other cores might have the data in Shared or Owned states. When another core, say Core 2, wants to modify the same data, it must first invalidate the other copies, forcing Core 1 to write back the data to memory or share it directly with Core 2. This process can cause significant coherence traffic. To reduce this traffic, data partitioning or reducing shared variables can help by minimizing the number of cores that need to access or modify the same data. Additionally, using local copies of the data (replication) when possible can reduce coherence overhead.
- In a multicore processor system with 8 cores, the cache coherence is maintained using the write-update protocol. Core 2 writes to a shared variable, and immediately afterward, Core 6 reads the same variable. Explain the sequence of events that occur to ensure cache coherence in this system. Now, Core 1 and Core 3 simultaneously attempt to modify different variables in the same cache line. Discuss how the system handles this situation, considering the potential for false sharing.
Solution: In the write-update protocol, when Core 2 writes to a shared variable, the system broadcasts the updated value to all other caches that have the variable. Core 6, upon reading the variable, retrieves the updated value from its cache, ensuring coherence without having to fetch from memory. If Core 1 and Core 3 modify different variables in the same cache line, the cache coherence system will treat this as a shared cache line update, potentially leading to false sharing, where unnecessary coherence updates occur for data that is not truly shared. To handle this, the system may broadcast frequent updates, leading to performance degradation. One way to mitigate false sharing is through cache line padding to ensure different variables are placed in separate cache lines.
- A parallel computing system uses a shared-memory model with 64 processors. Each processor has its own private L1 and L2 caches, and they share an L3 cache. Given that the system uses a directory-based cache coherence protocol, explain how the directory manages the state of cache blocks when one processor writes to a block that is cached in other processors’ L2 caches. How does the directory prevent write serialization issues? What are the key challenges in scaling this directory protocol to 128 processors?
Solution: In a directory-based protocol, the directory keeps track of which processors have cached copies of a memory block. When a processor writes to the block, the directory sends invalidation or update messages to all processors holding the block in their caches. To prevent write serialization issues, the directory ensures that only one processor can have write access to the block at any time (Modified state), and other processors are either invalidated or downgraded to a Shared state. As the number of processors increases to 128, the directory becomes a bottleneck due to the increased storage and communication overhead needed to track coherence. One way to mitigate this is through distributed directories, where coherence information is spread across multiple nodes to reduce the load on a single directory.
- A warehouse-scale computer (WSC) is being used for a large-scale web service. The WSC uses thousands of processors, each with private L1 caches and shared L2 caches. These processors communicate through a distributed directory-based cache coherence protocol. Explain the scalability challenges that arise in maintaining coherence in such a large system. How does the distributed nature of the directory help manage coherence across thousands of processors? Propose an optimization that can further reduce coherence overhead in this system.
Solution: In a WSC, maintaining cache coherence across thousands of processors is challenging due to the sheer volume of coherence traffic. A distributed directory helps manage this by breaking up coherence management responsibilities across multiple nodes. Each node is responsible for tracking the cache lines it owns, reducing the need for a centralized directory. However, as the system grows, even a distributed directory can become a bottleneck due to the need to maintain coherence across many nodes. One optimization is to use hierarchical directories, where smaller groups of processors share a local directory, and only coherence issues between groups need to go to a higher-level directory. Another optimization is to implement coherence filtering, which reduces unnecessary coherence messages for memory blocks that are not shared across multiple processors.
- In a parallelized database system, multiple threads are running on a 16-core multicore processor. The database system is heavily read-intensive, and the cache coherence protocol used is MESI. Suppose one thread on Core 7 frequently updates records in the database, while threads on other cores primarily perform read operations. Explain how the MESI protocol manages the coherence of the cache lines containing these records. What performance issues could arise if the system switches to the MOESI protocol? Justify your answer with respect to cache coherence and memory bandwidth.
Solution: In the MESI protocol, when Core 7 modifies a cache line, it transitions to the Modified state, and any copies in other cores’ caches are invalidated. When other threads (e.g., on Core 3) attempt to read the modified data, they will experience cache misses and retrieve the latest version from Core 7’s cache (if cache-to-cache transfers are supported) or from memory. If the system switches to the MOESI protocol, the cache line could move to the Owned state, allowing multiple cores to read the data from Core 7’s cache without fetching from memory. This can reduce memory bandwidth usage but could introduce additional complexity in managing cache line states when multiple cores are reading and modifying shared data.
Consider a multicore system using TLP to run several parallel tasks. Each core has its own L1 and L2 caches, and they all share an L3 cache. The system uses the write-back policy with a write-allocate strategy. During a parallel computation, Core 4 writes to a memory block that is shared among several cores. When Core 6 tries to read the same block, the system experiences a cache miss. Explain the steps involved in maintaining coherence and ensuring consistency between Core 4’s write and Core 6’s read. Now, assume the system switches to a no-write-allocate strategy. How would this change the cache coherence behavior and performance in such a scenario?
Solution: With the write-back policy and write-allocate strategy, when Core 4 writes to a shared memory block, it keeps the updated block in its cache and marks it as dirty (Modified). When Core 6 tries to read the same block, it experiences a cache miss, and the system fetches the block from Core 4’s cache, ensuring coherence by updating Core 6’s cache with the latest data. In a no-write-allocate system, when Core 4 writes to the block, it bypasses the cache and writes directly to memory. When Core 6 tries to read the block, it would retrieve the data directly from memory, reducing the load on Core 4’s cache but possibly increasing memory traffic. This strategy can improve performance for workloads with infrequent writes, but it may reduce cache efficiency if the same block is frequently written to and read from.