Magnetic drives, commonly known as hard disk drives (HDDs), store and retrieve data using magnetic storage. This technology involves several key components and concepts which work together to perform the operations of reading from and writing to the disk. Let’s delve into the structure and the terms associated with magnetic drives:
Platters
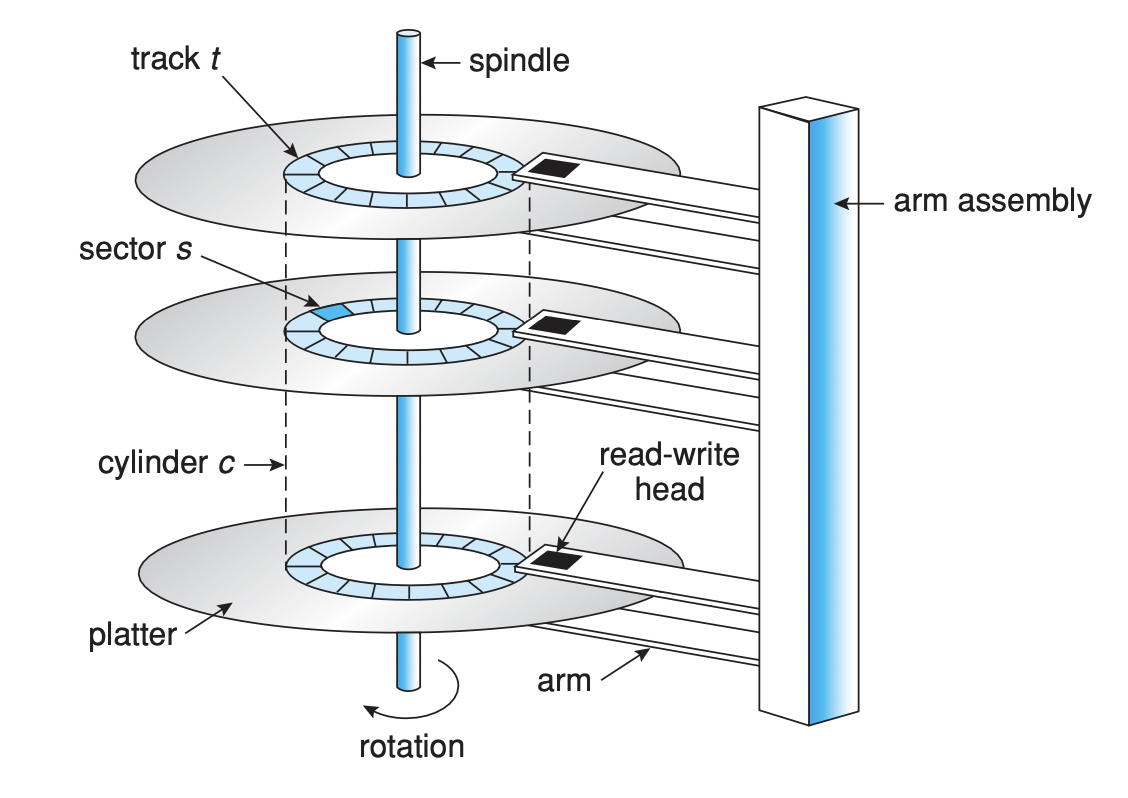
The platter is the circular disk within the HDD on which data is magnetically recorded. It's made of a non-magnetic material, usually aluminum or glass, coated with a thin layer of magnetic material. Platters spin at a constant rate during operation, measured in revolutions per minute (RPM).
Tracks
Tracks are concentric circles on the surface of the platter. Data is written to and read from these tracks by disk heads. Each platter has thousands of tracks, and the number of tracks is one of the factors determining the storage capacity of the drive.
Sectors
A sector is the smallest unit of data on a magnetic drive, traditionally 512 bytes, although newer drives use a 4K (4096-byte) sector size. Sectors are subdivisions of a track, so a single track will contain multiple sectors.
Blocks
Blocks and sectors are often used interchangeably in the context of HDDs. However, a block can refer to a group of sectors that the operating system reads or writes as a single unit. The block size is determined by the file system.
Disk Heads
Disk heads are the components that read and write data on the platter surfaces. There's one head for each platter surface, and they move together radially across the platters to access different tracks. The heads float above the platter surface on a cushion of air generated by the spinning platters.
Cylinders
A cylinder is a set of tracks located at the same position on each platter, accessible without repositioning the heads. Since the heads move in unison, when they read or write data, they can access the same track number on each platter, forming a cylinder.
RPM (Revolutions Per Minute)
RPM refers to the number of times a platter completes a full rotation in one minute. Common RPM rates for HDDs are 5400 and 7200, although higher-performance drives, such as those used in servers, may operate at 10,000 or even 15,000 RPM.
Seek Time
Seek time is the time it takes for the disk heads to move to the correct track where the data is stored or will be written. It is one of the primary measures of the drive's performance, with lower seek times indicating faster performance.
Rotational Latency
Rotational latency is the delay waiting for the platter to spin to the correct position under the disk head for reading or writing. This latency depends on the speed of the platter's rotation (RPM).
Random-Access Time
Random-access time is the sum of the seek time and the rotational latency. It represents the total time it takes to read or write data at a random location on the disk. This is a critical performance metric for drives, especially in applications requiring rapid access to a large number of files or datasets.
In modern magnetic disk drives, data is organized and accessed through a straightforward, linear structure of logical blocks, where a logical block represents the smallest chunk of data that can be transferred. Typically, each of these blocks holds 512 bytes of data, though it's possible to format some disks differently, for example, to increase the logical block size to 1,024 bytes.
These logical blocks are arranged sequentially across the disk's sectors, starting with Sector 0 located on the outermost track of the outermost cylinder. The sequence fills up each track of the first cylinder before moving inward to the next cylinder, covering all tracks in a stepwise inward fashion until it reaches the innermost cylinder.
The operating system aims to use hardware in the most efficient way possible, which, for disk drives, means achieving quick access times and high data transfer rates, or disk bandwidth. Access time on magnetic disks includes two primary parts: the seek time, which is the duration needed for the disk arm to position the heads over the correct cylinder where the desired data is located, and the rotational latency, which is the wait time until the disk rotates the specific sector under the read/write head.
Disk bandwidth refers to the rate at which data can be transferred to or from the disk, calculated by dividing the total amount of data transferred by the total time from the initial request to the end of the last data transfer. Managing the sequence in which disk I/O (Input/Output) requests are processed can enhance both access times and bandwidth.
When a process needs to perform an I/O operation with the disk, it issues a system call to the operating system, detailing whether the operation involves reading from (input) or writing to (output) the disk, the disk address for the data transfer, the memory address for the data, and the number of sectors involved in the transfer. If the specific disk drive and its controller are not currently engaged, the operation can proceed right away. Otherwise, the request joins a queue of pending operations for that disk drive.
In systems where multiple programs are running simultaneously, this queue can get quite long. Therefore, once an I/O request is completed, the operating system must decide which of the pending requests to handle next. This decision is guided by various disk scheduling algorithms, which are designed to optimize the efficiency of disk operations.
FCFS, standing for First-Come, First-Served, is one of the simplest forms of disk scheduling algorithms. It operates under a straightforward principle: process disk requests in the exact order they arrive, regardless of the data's location on the disk. This method mirrors the queue system seen in everyday life, such as in banks or stores, where the first person to arrive is the first to be served.
When a disk I/O request is made, it is placed at the end of the queue. The disk scheduling system processes requests from the front of the queue, moving sequentially to the next request only after the current one is completed. This approach does not consider the physical location of the data on the disk, leading to simplicity in implementation but potentially increased seek times compared to other algorithms that optimize for the disk head's movement.
Imagine a disk with 200 cylinders numbered 0 to 199. Suppose the disk head is currently at cylinder 50, and there are disk requests queued up for cylinders in the following order: 35, 90, 130, 15, and 145.
Here's how FCFS would handle these requests:
First request for cylinder 35: The disk head moves from 50 to 35, traversing 15 cylinders.
Next, for cylinder 90: The head moves from 35 to 90, traversing 55 cylinders.
Then to cylinder 130: The movement is from 90 to 130, traversing 40 cylinders.
Followed by cylinder 15: This requires moving from 130 back to 15, traversing 115 cylinders.
Finally, to cylinder 145: The head moves from 15 to 145, traversing 130 cylinders.
The total number of cylinders traversed to satisfy all requests is 355.
Pros and Cons of FCFS Disk Scheduling
Pros:
Simplicity: FCFS is straightforward to understand and implement.
Fairness: Every request is treated equally, with no prioritization, ensuring that earlier requests are completed first.
Cons:
Inefficiency in seek times: By not considering the physical locations of requests, FCFS can result in longer total seek times, especially for disks with a large number of requests spread across the disk.
Not optimal for systems with high I/O demand: In systems where disk performance is critical, the increased seek times can lead to bottlenecks and decreased overall system performance.
Despite its simplicity, the inefficiency of FCFS in handling disk requests, especially under heavy load or with a disk layout that has requests scattered widely, often leads to the consideration of more sophisticated algorithms like Shortest Seek Time First (SSTF), SCAN, or C-SCAN, which aim to minimize the seek time and improve overall disk performance.
The Shortest Seek Time First (SSTF) disk scheduling algorithm is an optimization over the simple FCFS (First-Come, First-Served) method, aimed at reducing the total seek time, which is the time the disk head needs to move between tracks. SSTF selects the disk I/O request that is closest to the current head position, thereby minimizing the distance the head must move on average, compared to processing requests in the order they arrive.
In SSTF scheduling, whenever the disk is ready to process a new request, it looks at the queue of pending requests and selects the one with the minimum seek time from the current head position. This process repeats for each request, with the algorithm always choosing the next nearest request to the current head position.
Consider the same disk setup with 200 cylinders (numbered 0 to 199) and a disk head initially at cylinder 50. The pending requests are for cylinders 35, 90, 130, 15, and 145.
Here's how SSTF would handle these requests:
Initial position at cylinder 50. The closest request is for cylinder 35 (15 cylinders away), so it's served first.
Next closest request is for cylinder 15, 20 cylinders away from the last position (35), so it's served next.
After serving cylinder 15, the closest request is for cylinder 90, 75 cylinders away.
From cylinder 90, the next closest request is for cylinder 130, 40 cylinders away.
Finally, the request for cylinder 145 is served, which is 15 cylinders away from 130.
In this scenario, the total number of cylinders traversed is 165 (15 + 20 + 75 + 40 + 15), which is significantly less than the 355 cylinders traversed in the FCFS example.
Pros and Cons of SSTF Disk Scheduling
Pros:
Reduced Seek Time: By always choosing the closest request, SSTF significantly reduces the total seek time compared to FCFS, improving disk utilization and overall system performance.
Efficient for Systems with Sparse Requests: In environments where disk I/O requests are not densely packed, SSTF can offer substantial performance improvements.
Cons:
Potential for Starvation: Since SSTF prioritizes requests based on their proximity to the current head position, requests that are far from the current set of frequently accessed cylinders may experience long wait times or even starvation.
Variable Service Time: The time it takes for a request to be served can vary widely, depending on its position relative to other requests, leading to unpredictability in performance.
Requires State Information: SSTF needs to know the current position of the head and the positions of all pending requests, adding complexity to its implementation.
SSTF is more efficient than FCFS in terms of seek time, making it better suited for systems where disk performance is a bottleneck. However, its tendency to favor requests that are near the current head position can lead to unfairness among requests, with some potentially waiting indefinitely if they are consistently further away than others.
The SCAN disk scheduling algorithm, often referred to as the "elevator" algorithm, improves upon the concepts of First-Come, First-Served (FCFS) and Shortest Seek Time First (SSTF) by moving the disk arm across the entire disk in one direction, satisfying all requests until it reaches the end of the disk, then reversing direction and satisfying requests on the way back. This method mimics the movement of an elevator in a building, hence its nickname.
In SCAN scheduling, the disk head starts at one end of the disk (or at the current position) and moves towards the other end. As it moves, it serves all the requests it encounters along its path. Upon reaching the last cylinder in one direction, the head reverses direction and again serves all pending requests it encounters on its return path. This process repeats, ensuring that requests are served in a more uniform manner compared to FCFS and SSTF.
Let's consider the same disk with 200 cylinders, numbered 0 to 199, with the disk head starting at cylinder 50. Pending requests are for cylinders 35, 90, 130, 15, and 145.
Here's how SCAN would address these requests, assuming the head initially moves towards the higher numbered cylinders:
Starting at cylinder 50, the head moves towards cylinder 199.
The head first serves the request at cylinder 90, then cylinder 130, and finally cylinder 145, as these are on its path.
Upon reaching cylinder 199, the head reverses direction.
On its way back, it serves the remaining requests: cylinder 35 and then cylinder 15, which are now on its path towards cylinder 0.
The total distance covered depends on whether the head actually travels all the way to the end of the disk or turns around after serving the last request. If it turns around at cylinder 145 and then goes back to 15, the total number of cylinders traversed is significantly less than if it had followed each algorithm strictly without optimization.
Pros and Cons of SCAN Disk Scheduling
Pros:
Fairness: By covering all cylinders from one end to the other, SCAN ensures a more uniform service time for requests, compared to SSTF and FCFS.
Reduced Seek Time: SCAN typically offers a good balance between minimizing seek time and serving all requests in a timely manner.
Cons:
Potential for Longer Waits: Requests just missed by the head as it reverses direction may have to wait for the head to traverse the entire disk before being served.
Directional Bias: Requests in the direction of the initial head movement are served faster, potentially introducing some bias based on the starting position and direction of the head.
SCAN provides a middle ground between the simplicity and fairness of FCFS and the efficiency but potential unfairness of SSTF. By methodically scanning back and forth across the disk, it ensures that requests are served in a predictable pattern, reducing extreme variations in wait times and preventing starvation. This makes SCAN a popular choice for disk scheduling in systems where a balance between efficiency and fairness is desired.
The C-SCAN (Circular SCAN) disk scheduling algorithm, also known as the elevator algorithm, is designed to improve the efficiency and fairness of disk access by ensuring a more uniform wait time for requests across the disk. It's an enhancement over the SCAN algorithm, addressing some of its shortcomings, particularly around the treatment of requests at the extreme ends of the disk.
In C-SCAN scheduling, the disk head moves in a single direction (either towards the highest or the lowest cylinder) and processes all the requests in its path. Once it reaches the end of the disk, however, instead of reversing direction as in SCAN, it jumps directly to the opposite end of the disk and continues processing requests in the same direction. This creates a circular-like motion, hence the name "Circular SCAN" or "C-SCAN."
The key distinction between SCAN and C-SCAN is how they handle the turnaround: C-SCAN effectively treats the disk as a loop, which helps to normalize service times for requests at the edges of the disk.
Assuming a disk with 200 cylinders (numbered from 0 to 199), with the head starting at cylinder 50, and requests queued for cylinders 35, 90, 130, 15, and 145.
Here's how C-SCAN would handle these requests if the head moves towards the higher-numbered cylinders:
Start at cylinder 50. The head first moves towards cylinder 90, then to 130, and finally to 145, serving requests as it passes.
Upon reaching the end (cylinder 199), the head jumps to the opposite end (cylinder 0) without serving any request on this move.
The head then moves to serve requests at cylinders 15 and 35.
In this scenario, the total distance traversed by the head includes the initial pass to the highest request (145), the jump to the beginning (back to 0), and then the movement to serve the lowest requests (up to 35). The effective movement is from cylinder 50 to 199, then from 0 to 35.
Pros and Cons of C-SCAN Disk Scheduling
Pros:
Fair Treatment: By continuously moving in one direction before looping around, C-SCAN offers a more predictable and fair wait time for requests, especially beneficial for those at the edges.
Reduced Seek Time for Some Requests: The algorithm can offer reduced seek times, particularly for requests placed towards the end of the disk's traversal direction, as it avoids the head frequently changing direction.
Efficient for Uniform Workloads: The predictable movement can make C-SCAN efficient in environments where requests are uniformly distributed across the disk.
Cons:
Jump Overhead: The time taken for the head to jump from the last cylinder back to the first (or vice versa) without serving any requests could be seen as a waste, especially if there are no pending requests at the start of the disk.
Not Ideal for Sparse Workloads: If requests are concentrated in specific areas of the disk, the rigid traversal pattern of C-SCAN might lead to unnecessary traversal of empty regions, potentially increasing the average wait time.
C-SCAN's approach to disk scheduling provides a balance between efficiency and fairness, making it a good choice for systems that require predictable access times and can benefit from the orderly servicing of disk requests. However, the effectiveness of C-SCAN, like other disk scheduling algorithms, can vary depending on the specific workload and disk usage patterns.
The LOOK disk scheduling algorithm is a refinement of the SCAN algorithm, often referred to as the "elevator algorithm." LOOK improves upon SCAN by eliminating the unnecessary movement of the disk arm to the very end of the disk if there are no requests to be serviced in that direction. This makes the LOOK algorithm more efficient in terms of movement and time, especially when disk requests are not evenly distributed across the entire disk surface.
In the LOOK scheduling method, the disk head moves in one direction and services all the requests in that direction until it reaches the last request. Instead of continuing to the end of the disk, the head then "looks" for the next request in the opposite direction and changes course once it services the request furthest in its current direction. This process repeats, with the disk head changing direction only when there are no further requests to service in its current trajectory.
Consider a disk with 200 cylinders, numbered from 0 to 199, and suppose the disk head starts at cylinder 50. Let's say there are pending requests for cylinders at 35, 90, 130, 15, and 145.
Here's how LOOK would manage these requests:
Starting at cylinder 50, the disk head moves towards the higher numbered cylinders first, servicing the requests at 90, 130, and finally 145, as these are in the direction of its initial movement.
After servicing cylinder 145, the head "looks" for further requests in its current direction (towards the higher-numbered cylinders). Finding none, it reverses direction.
Moving back, it services the requests at cylinder 35 next. Then it continues moving towards the lower numbered cylinders to service the request at cylinder 15, which is the last in this direction.
By "looking" and reversing direction only when there are no further requests to process in the current direction, the disk head minimizes unnecessary travel, focusing instead on servicing requests more efficiently.
Pros and Cons of LOOK Disk Scheduling
Pros:
Reduced Unnecessary Movement: By not moving to the ends of the disk unless needed, LOOK reduces the overall distance the disk head travels, potentially lowering the average seek time.
Dynamic Adaptation: LOOK adapts dynamically to the distribution of requests, making it more efficient than algorithms like SCAN or C-SCAN in certain scenarios, especially when requests are clustered.
Fairness and Efficiency: LOOK balances between fairness and efficiency by ensuring that requests are serviced in both directions, but only as far as the last request in each direction, preventing starvation.
Cons:
Potential for Increased Overhead in Dense Request Environments: In scenarios where requests are densely packed, LOOK might result in more frequent direction changes than C-SCAN, potentially increasing the overhead.
Variable Performance: The performance gains of LOOK can be variable, heavily dependent on the specific distribution of disk requests. In some cases, it may not offer significant improvements over other algorithms.
LOOK offers a balanced approach to disk scheduling by adapting to the distribution of requests on the disk, providing efficiency gains in many typical scenarios. This adaptability makes it suitable for a wide range of systems, though its effectiveness can vary based on the specific workload and disk usage patterns.
The C-LOOK (Circular LOOK) disk scheduling algorithm is a variant of the LOOK algorithm, designed to further refine the process of servicing disk requests. Similar to C-SCAN, C-LOOK enhances the efficiency and fairness of disk access, particularly for requests near the edges of the disk. It operates by moving the disk head in one direction to service requests, but unlike C-SCAN, it doesn't go all the way to the end of the disk if there are no requests there. Instead, once it services the last request in one direction, it jumps directly to the closest request in the opposite direction.
In C-LOOK scheduling, the disk head moves in a designated direction (towards the higher or lower numbered cylinders) and services requests along the way. When it reaches the highest (or lowest) request in that direction, instead of continuing to the end of the disk or immediately reversing direction, it "looks" for the nearest request back in the starting point of its travel direction and jumps directly to it, skipping over any gaps where there are no requests. This jump does not service any requests during the movement, making it a direct leap to the next set of requests to be serviced.
Let’s use the same setup: a disk with 200 cylinders (0 to 199) and the disk head starting at cylinder 50. Requests are pending at cylinders 35, 90, 130, 15, and 145.
Here's the sequence under C-LOOK, assuming the head moves towards the higher-numbered cylinders:
From starting position at cylinder 50, the disk head moves towards the higher numbers, servicing requests at 90, 130, and 145 in turn.
After servicing the last request at 145, the head "looks" for any further requests in its direction. Finding none, it jumps directly to the lowest pending request, which is at cylinder 15, skipping over the unrequested cylinders.
The disk head then services the request at cylinder 15, and finally moves to cylinder 35 to service the last request.
In this example, after completing the highest request, the head makes a direct leap to the beginning of the queue in its servicing direction, optimizing the travel path by eliminating unnecessary traversal of the disk.
Pros and Cons of C-LOOK Disk Scheduling
Pros:
Efficient Handling of Edge Requests: By jumping directly to the next set of requests without traversing the entire disk, C-LOOK can efficiently handle requests near the disk edges, reducing overall seek time.
Reduced Disk Arm Movement: The direct jump from the last serviced request to the first request in the opposite direction minimizes unnecessary disk arm movement, potentially leading to faster overall performance.
Fairness: Similar to C-SCAN, C-LOOK offers a more predictable and fair access time across the disk by regularly servicing requests in a circular pattern.
Cons:
Jump Overhead: While the direct jump to the next set of requests can improve efficiency, it also introduces overhead, especially if the next request is far from the last serviced request.
Variable Performance: The performance benefits of C-LOOK can vary depending on the distribution and density of disk requests. In some scenarios, other algorithms may offer better efficiency.
C-LOOK strikes a balance between minimizing unnecessary disk head movement and providing fair service to all disk requests, making it a potentially effective choice for systems where request distribution is uneven or where minimizing seek time is a priority. Its efficiency and fairness make it suitable for many applications, though, like other disk scheduling algorithms, its performance can depend on specific workload characteristics.
A file in a computer is a digital unit of storage that contains data, such as text, images, audio, video, or software. It is stored on a storage device, such as a hard drive, SSD, or cloud storage, and is identified by a unique name and location in the file system of the computer. Files can be created, opened, modified, moved, copied, and deleted using file management systems or applications.
Files can have a variety of attributes that describe their properties and govern their usage and access. These attributes can vary slightly depending on the operating system (OS), but generally include the following:
Name: The identifier of the file. It typically includes a file name and extension (e.g., document.txt), where the extension indicates the file type or format.
Type: Determined by the file extension, it indicates the format of the file and what kind of data it contains (e.g., .txt for text files, .jpg for JPEG images).
Size: The amount of storage space the file occupies on the disk, usually measured in bytes, kilobytes (KB), megabytes (MB), gigabytes (GB), or terabytes (TB).
Location: The path to the file's directory or folder within the file system, indicating where the file is stored.
Permissions: Define who can read, write, or execute the file. This attribute is especially important in multi-user or networked environments. Permissions can specify access for the file owner, a group of users, and others.
Date and time stamps: Files have metadata that includes dates and times of creation, last modification, and last access. These timestamps help in organizing, sorting, and finding files.
Read-only status: Indicates whether a file can only be read or if it can also be written to or modified. This is a safety feature to prevent accidental changes.
Hidden status: Determines whether a file is visible or hidden from the default view in a directory. Hidden files are often system files or configuration files that users do not need to interact with regularly.
Archive bit: Used by backup software to indicate whether a file has been backed up. If the bit is set, the file has been changed since the last backup.
Compression: Indicates whether a file's data has been compressed to save space. Compressed files must be decompressed before their content can be accessed.
Encryption: Indicates whether a file's content is encrypted for security. Encrypted files can only be accessed by users who have the decryption key.
Ownership: Specifies the user and/or group that owns the file, which typically affects permissions and access control.
Operations on files are fundamental actions that users and software can perform to manage and manipulate data stored in files on a computer. These operations vary in complexity and purpose, from basic management tasks like creating and deleting files to more advanced manipulations like encrypting or compressing data. Here's a detailed look at common file operations:
1. Creating Files
Purpose: To generate a new file on the storage device.
Process: Involved selecting a location and specifying a file name. The system allocates space and initializes the file, setting default attributes like permissions and timestamps.
2. Opening Files
Purpose: To access and read the contents of a file, or to prepare it for writing.
Process: The system checks permissions, then provides a file descriptor or handle that software uses to read from or write to the file.
3. Reading Files
Purpose: To access the data stored in a file.
Process: After opening, the file's contents can be read into memory for processing or display. The system reads the data starting from the current file pointer position, which then advances by the amount of data read.
4. Writing to Files
Purpose: To modify a file by adding new data or altering existing data.
Process: Similar to reading, but data from memory is written to the file at the current file pointer position, which may overwrite existing data or append to the file, depending on the mode used when opening the file.
5. Closing Files
Purpose: To end access to a file and ensure that all changes are saved to the storage device.
Process: The file descriptor or handle is released, any buffered data is written to storage, and the file's attributes (like last access time) are updated.
6. Deleting Files
Purpose: To remove a file from the storage device.
Process: The system removes the file's entry from the file system directory and marks its storage space as available for reuse. The data may still exist on the storage medium until overwritten.
7. Moving Files
Purpose: To change a file's location within the file system.
Process: This can involve changing the file's directory path or moving it to a different storage device. The file's contents are not changed, but its location attribute is updated.
8. Copying Files
Purpose: To create a duplicate of a file in a new location, while keeping the original.
Process: The system reads the file's data and writes it to a new file, preserving the original file's content but not necessarily its permissions or timestamps.
9. Renaming Files
10. Changing File Attributes
Purpose: To modify a file's metadata, such as permissions, read-only status, and hidden status.
Process: System calls or file management tools are used to update the desired attributes.
11. Archiving Files
Purpose: To combine multiple files into a single archive file, often compressing them to save space.
Process: Specialized software reads the files, compresses their data (optional), and writes the data to a new file in a specific archive format.
12. Encrypting Files
Purpose: To secure a file's contents by encoding them in such a way that only authorized users can access the original data.
Process: Encryption software transforms the file's data using a cryptographic algorithm and a secret key. Decrypting the file requires the corresponding decryption key.
13. Compressing Files
Purpose: To reduce a file's size by using algorithms to eliminate redundancy or represent data more efficiently.
Process: Compression software rewrites the file's data in a compressed format. Decompression is required to access the original data.
14. Linking Files (Hard and Soft Links)
Essentially, files like source codes, executables, and text documents have specific formats that both the operating system and the applications using them understand. For an executable file, for example, the operating system needs to know its structure to execute it properly, like where it starts in memory.
However, incorporating support for multiple file structures directly into an operating system can bloat its size because it must include the code to manage these structures. Imagine an operating system designed to handle only text and executable files; introducing a new, encrypted file type poses a challenge since it doesn't fit neatly into either category. It's not just plain text because it's encrypted, and it's not an executable, although it may look like a binary file. Users might have to find a workaround or give up their encryption to comply with the operating system's limitations.
Some operating systems, like UNIX and Windows, keep things simple by treating files as a series of bytes without assigning any inherent structure. This approach grants maximum flexibility but places the onus on application developers to interpret file structures on their own. Nonetheless, all operating systems must recognize at least one file structure: that of executable files, to load and run programs.
Files are stored on disks in blocks of a fixed size, leading to a mismatch between the logical size of the data (how the application sees it) and the physical size (how it's stored on disk). Operating systems or applications must then pack these logical records into the fixed-size physical blocks, a process that can lead to wasted space, known as internal fragmentation, because the last block of a file may not be fully used.
Sequential access is a fundamental method for reading from and writing to files, where operations on the file's data are carried out in a linear order. This method is intuitive and mirrors how one might read a book, starting from the beginning and proceeding page by page until the end. Sequential access is particularly common in applications like text editors and compilers, where processing data in a straight, ordered manner is essential.
In sequential access, a file is processed record by record in a predetermined sequence. Each "record" refers to a unit of data—this could be a line of text in a text file, for instance. The system maintains a file pointer, which is essentially a marker that keeps track of the current position within the file. This pointer moves automatically as the file is read or written.
Read Operation (read next())
Function: This operation reads the next portion of the file—i.e., the next record—based on the current position of the file pointer.
File Pointer Movement: After reading a portion, the file pointer advances to the beginning of the subsequent record. This automatic advancement ensures that subsequent read next() calls will process the file in order, moving through the file's contents progressively.
Write Operation (write next())
Function: This operation appends data to the end of the file. The new data becomes the latest record.
File Pointer Movement: Upon writing, the file pointer moves to the end of the newly added material, marking the new end of the file. This positioning means the next write operation will further append data to this new endpoint.
While the basic premise of sequential access is straightforward—read or write the next record—some systems offer additional functionalities to enhance this access method:
Resetting: The ability to reset the file pointer to the beginning of the file allows a program to start reading or writing from the start again, without the need to reopen the file.
Skipping Records: Some systems may permit skipping forward or backward by a specified number of records (e.g., n records). This capability, while still maintaining a sequential pattern, offers a degree of flexibility in accessing the file's data. However, this function might be limited; for example, some systems may only allow skipping one record at a time (n = 1).
Use Cases
Applications that process data in a linear fashion—such as reading a log file, processing a data stream, or compiling code—benefit from sequential access. This method is straightforward, with minimal overhead for managing the file pointer, making it ideal for many common file operations.
In summary, sequential access is a vital file operation method that facilitates ordered reading and writing operations. Its simplicity and efficiency make it widely used in various applications, despite the existence of more flexible methods like random access for specific use cases.
Direct access, also known as relative access, is a method of file handling that enables rapid reading and writing of records in a non-sequential order. This method contrasts with sequential access, where records are processed in a linear fashion. Direct access is particularly well-suited to disk storage systems, which inherently allow for random access to any point in a file, making it possible to quickly navigate to and manipulate specific records without the need to proceed through the file in order.
In direct access, a file is conceptualized as a sequence of fixed-length blocks or records, each uniquely identifiable by a number or index. This structure facilitates the rapid location and manipulation of specific records based on their index, without the necessity of reading through preceding records. Operations in direct access are characterized by the ability to directly read or write any given block by specifying its index, offering a high degree of flexibility and efficiency in file management.
Use Cases
Direct access is invaluable in scenarios requiring immediate retrieval or update of data stored in large files, such as databases or airline reservation systems. For example, in an airline reservation system, each flight's details, like the number of available seats, might be stored in a block corresponding to the flight number. When a query is made for flight 713, the system directly accesses block 713 to retrieve or update the flight's information.
Operations in Direct Access
To facilitate direct access, file operation commands are adapted to include the block number as a parameter:
An alternative approach maintains the read next() and write next() operations used in sequential access but introduces a position file(n) operation to move the file pointer to the block n. Subsequent read next() or write next() operations will then act from this new position, enabling a blend of direct and sequential access methods as needed.
Addressing and Allocation
The block numbers used in direct access are typically relative, serving as indexes from the beginning of the file. This system allows the operating system more flexibility in file storage and allocation while also preventing unauthorized access to unrelated parts of the file system. The translation of a request for a specific record into an actual input/output operation is straightforward, thanks to the fixed size of logical records. To access record N, the system computes its start position as L * N, where L is the length of each record, and performs the necessary read or write operation.
The directory in a computer file system serves as a critical interface, translating human-readable file names into the detailed directory entries the system uses to track files. The organization of the directory is key to efficiently performing a variety of essential file operations. Below, we explore various aspects and schemes of directory organization, taking into account the operations that need to be supported.
The operations that need to be supported by a directory structure include:
Searching for a File: The capability to quickly locate the entry for a specific file within the directory. This operation is vital because it allows users to access files based on their symbolic names. Additionally, users may need to find files matching certain patterns, indicating the necessity for a directory system that can support complex search queries.
Creating a File: When users or applications need to add new data, the directory must provide a mechanism to create a new file and register its entry. This process involves allocating space for the file, setting up its attributes, and adding a corresponding entry in the directory.
Deleting a File: The directory must allow for the removal of files that are no longer needed. Deleting a file involves removing its directory entry and freeing up the space it occupied for reuse.
Listing a Directory: Users often need to see the contents of a directory, including the names of files and potentially their attributes (such as size, type, and modification date). This operation requires the directory to enumerate its entries in a user-friendly manner.
Renaming a File: The need to rename files arises when their content or the context of their use changes. Renaming might also be used to reorganize files within the directory structure. This operation requires updating the file's directory entry to reflect the new name without altering the file's location on the storage medium, unless the directory structure logically requires such a move.
Traversing the File System: For maintenance, backup, or organizational purposes, it might be necessary to visit every directory and file within the system. This operation is crucial for creating comprehensive backups and ensuring the integrity and reliability of the file system.
To support these operations effectively, various directory structure schemes can be implemented, each with its advantages and challenges:
Single-Level Directory: The simplest form, where all files are contained within a single directory. While easy to implement, it quickly becomes impractical as the number of files grows, leading to difficulties in file management and name conflicts.
Two-Level Directory: This structure introduces a separate directory for each user, enhancing organization and security by isolating users' files from one another. However, it still limits the complexity of file organization that can be handled.
Hierarchical (Tree-Structured) Directory: Most modern file systems use this approach, organizing files into a directory tree that can have multiple levels. This structure supports complex and nested file organization, allowing users to create a more logical and intuitive organization of their files.
Acyclic-Graph Directory: An extension of the hierarchical directory that allows directories to be shared among different branches of the directory tree. This scheme introduces the possibility of multiple paths to the same file but requires special handling to avoid issues like infinite loops while traversing the directory structure.
General Graph Directory: The most flexible structure, allowing any directory to link to any other, including the possibility of circular references. This structure can represent the most complex relationships between files and directories but is also the most challenging to manage, especially in terms of preventing and handling cycles.
Each directory structure scheme offers a balance between flexibility in file organization and the complexity of managing the directory itself. The choice of directory structure has a profound impact on the efficiency of file system operations and the overall user experience.
Understanding a UNIX file system involves grasping several key concepts and how they interrelate to manage storage, directories, files, and file access efficiently. These concepts include blocks, boot control blocks, superblocks, inodes, file descriptors, and more. Let's explore these elements and their roles in a cohesive way.
Basic Concepts
Block: The basic unit of data storage in UNIX file systems. A block can be of a fixed size (commonly 512 bytes, 1 KB, 2 KB, or more) and is used to store data of files and directories. The use of blocks facilitates efficient disk space management, allowing the file system to allocate, read, and write data in chunks.
Boot Control Block: Also known as the boot block, it contains the bootstrap loader code. This special area on the disk is read by the computer's bootloader during the boot process. The boot control block is crucial for starting the operating system, as it contains the instructions needed to load the kernel and other startup configurations.
Superblock: Stores metadata about the file system, such as its size, the number of files it can store, the block size, the list of free blocks, and the inode list. The superblock acts as a central reference point for managing the file system's structure and resources.
Inode: Short for "index node," an inode is a data structure that stores metadata about a file or a directory. This metadata includes attributes like file size, ownership, permissions, timestamps (for creation, last modification, and last access), and pointers to the data blocks where the file's actual data is stored. Each file or directory is uniquely identified by its inode number within the file system.
File Descriptor: A file descriptor is an abstract indicator used by the operating system to access a file or a directory. When a file is opened, the operating system creates a file descriptor, usually represented as a non-negative integer, which is then used in system calls to read from, write to, or perform operations on the file.
Implementation of UNIX File System
The UNIX file system is a hierarchical structure, starting with the root directory (/) and branching into subdirectories and files. Here's how these concepts come together:
At the Beginning: When a UNIX system boots, the bootloader accesses the boot control block to load the kernel and initiate the operating system.
File System Layout: The file system is divided into several sections, beginning with the boot block, followed by the superblock, which is crucial for the overall file system's operation because it contains essential metadata.
Organizing Files and Directories: Each file and directory is associated with an inode, which stores metadata and block pointers. The data blocks do not contain names; they only have raw data. The association between file names and inodes is maintained in directories. A directory is a special type of file that lists names and corresponding inode numbers. This structure allows multiple names (hard links) to refer to the same inode.
Accessing Files: When a program wants to access a file, it typically goes through these steps:
The program requests to open a file by name.
The operating system searches the directory structure starting from the root (or current directory, depending on the path provided) to find the file name and its associated inode number.
Once the inode is located, the system reads the inode to access file metadata and the pointers to data blocks.
A file descriptor is created and returned to the program, which then uses it for further operations like reading or writing.
Navigating the File System: The hierarchical directory structure allows users and programs to navigate and organize files efficiently. Commands and system calls translate user requests into operations on inodes and data blocks, abstracting the underlying complexity.
Special Files: The UNIX file system also supports special file types, such as character and block devices, which are accessed through files in the /dev directory. These special files allow programs to interact with hardware devices using file I/O operations.
This cohesive interplay of blocks, inodes, file descriptors, and other elements enables the UNIX file system to manage data robustly and efficiently. The design facilitates a clear separation between file metadata and data, supports a flexible directory hierarchy, and provides a standardized interface for file operations.
Contiguous, linked, and indexed allocations are three primary methods used in file systems to manage how files are stored on disk. Each method has its advantages and disadvantages, influencing the efficiency of file access, storage utilization, and system performance. Let's delve into each of these allocation methods in detail.
Contiguous Allocation
Description: In contiguous allocation, a file occupies a set of contiguous blocks on the disk. When a file is created or written for the first time, the file system finds a sufficient number of free blocks in sequence and stores the file's data within this contiguous block span.
Advantages:
Simple to Implement: The file system only needs to keep track of the starting block and the length (number of blocks) of the file.
Efficient Access: Reading a file is fast because disk heads move minimally between consecutive blocks, supporting efficient sequential access and even direct jumping within the file.
Disadvantages:
Fragmentation: Over time, the disk can become fragmented, with free space divided into small, non-contiguous sections, making it difficult to find contiguous space for new files or for files that grow in size.
File Size Limitation: The file size must be known at creation time to allocate enough contiguous space, limiting dynamic file growth.
Linked Allocation
Description: In linked allocation, a file consists of a chain of blocks that do not need to be contiguous. Each block contains a pointer to the next block in the file, along with the data. The file directory contains the pointer to the first block, and the last block points to a null value indicating the end of the file.
Advantages:
Flexibility in File Size: Files can grow dynamically, with new blocks added to the end of the chain as needed.
Reduced Fragmentation: Since blocks do not need to be contiguous, there's less concern about fragmentation affecting file allocation.
Disadvantages:
Overhead and Slower Access: Each block contains a pointer, reducing the amount of usable space per block. Sequential access requires reading blocks in sequence, which can be slower due to the scattered nature of block locations.
Reliability Concerns: If a pointer is lost or corrupted, it can result in losing access to the rest of the file.
Indexed Allocation
Description: Indexed allocation seeks to combine the advantages of contiguous and linked allocations while mitigating their downsides. Each file has an index block, which is an array of pointers to the actual data blocks. The file directory contains the address of the index block, and the index block contains the addresses of the individual data blocks.
Advantages:
Direct Access: Unlike linked allocation, indexed allocation allows direct access to file blocks, improving read/write speeds for non-sequential access patterns.
Dynamic File Growth: Files can grow by adding new pointers to the index block or additional index blocks, without the need for contiguous space.
Efficient Use of Space: Reduces fragmentation and maximizes disk utilization.
Disadvantages:
Index Block Overhead: The index block itself consumes disk space, which can be significant for very large files requiring multiple index blocks.
Complexity: The file system implementation is more complex due to managing index blocks, especially for very large files that may require multi-level indexing.
In summary
Contiguous Allocation: Offers simplicity and fast access but suffers from fragmentation and fixed file size issues.
Linked Allocation: Provides flexibility for file size and eliminates fragmentation problems but introduces access overhead and potential reliability issues.
Indexed Allocation: Attempts to provide the benefits of both contiguous and linked allocations, offering direct access with dynamic file growth capability, albeit with increased complexity and overhead for managing index blocks.
In the vast ecosystem of computer devices, we encounter a wide variety of hardware, from storage devices like hard drives and USBs to human-interface gadgets such as keyboards and screens, and even highly specialized equipment like the controls in an aircraft. Despite this diversity, understanding how these devices connect to and interact with a computer boils down to a few key concepts involving communication methods, hardware structures, and software interfaces.
Communication and Connection
Devices connect to a computer system either physically, through cables, or wirelessly, through the air. This connection is established through ports (like USB or serial ports) for individual devices, or buses for multiple devices. A bus is essentially a communication highway that multiple devices can use to send and receive data from the computer, based on a specific set of electrical signals and protocols.
For example, if we have a series of devices connected one after the other and eventually to the computer, this setup is known as a daisy chain. It functions like a bus, allowing each device to communicate through a shared connection. Buses are crucial in computer architecture for linking various components, from fast devices like hard drives connected via a SCSI bus to slower peripherals like keyboards connected through USB.
Controllers
At the heart of device communication lies the controller, a piece of hardware responsible for managing the interactions between the computer and a device. Controllers vary in complexity: a serial-port controller might be a simple chip on the motherboard, while a SCSI bus controller could be an elaborate circuit board with its own processor and memory, designed to handle intricate protocol messages.
Controllers use registers for exchanging data and control signals with the computer's processor. These registers can be manipulated directly through I/O instructions, where the processor sends specific bit patterns to perform operations, or through memory-mapped I/O, where device registers are treated as memory addresses that the processor can read from or write to.
Memory-Mapped I/O vs. I/O Instructions
Memory-mapped I/O integrates device controls within the computer's address space, making device interaction as straightforward as reading from or writing to memory locations. This method is particularly efficient for high-volume data transfers, such as updating graphics displays. However, it also poses a risk of accidental modification due to software errors, highlighting the importance of protected memory systems.
Conversely, using I/O instructions to interact with devices involves specifying exact port addresses for data transfer, which can be more cumbersome but provides a more controlled environment for device interactions.
I/O Ports and Registers
An I/O port typically comprises four main registers: status, control, data-in, and data-out. These registers play distinct roles in device communication:
Data-in: For reading input data from the device.
Data-out: For sending output data to the device.
Status: For reading the current state of the device, including operation completion and error detection.
Control: For issuing commands or changing the device's operational mode.
Some controllers may include FIFO (First In, First Out) chips to buffer bursts of data, enhancing the controller's capacity to handle input and output efficiently.
In modern computing, the interaction between a computer (the host) and its peripherals (like keyboards, hard drives, and network cards) relies on a finely tuned communication process. This process involves several core concepts and mechanisms, such as handshaking, polling, interrupts, and priority systems, to manage data transfer efficiently and effectively.
Handshaking and Polling
The concept of handshaking is similar to how two people might agree on when to meet by exchanging messages. In computing, it's a way for the host and a device (through its controller) to signal readiness and coordinate actions. For example, when the host wants to send data to a device, it waits (a process known as polling) until the device signals it's not busy. Then, the host sends the data along with a signal that it's ready for the device to process. Once the device finishes its task, it clears the signals, indicating it's ready for more instructions.
Polling is like repeatedly checking your phone for a message — efficient if you expect a reply soon but wasteful if the wait is long. If the device takes time to become ready, the host wastes time that could be spent on other tasks.
Interrupts: A More Sophisticated Approach
Interrupts are a solution to the inefficiency of polling. Instead of the host continuously checking if a device is ready, the device sends a direct signal (an interrupt) to the host when it needs attention. This allows the host to work on other tasks and only deal with the device when necessary. It's akin to setting your phone to notify you of messages so you can focus on other things until you're alerted.
Upon receiving an interrupt, the host temporarily stops what it's doing, saves its current state, and handles the request from the device. After addressing the device's needs, the host resumes its previous activity. This system is crucial for managing the numerous devices a computer might be communicating with simultaneously, ensuring timely responses to all.
Modern operating systems must juggle multiple devices and requests, not all of which are equally urgent. To manage this, they use priority systems within the interrupt mechanism. Some interrupts (like those indicating a severe error) are non-maskable and always get immediate attention. Others can be temporarily blocked (masked) to ensure that critical tasks aren't interrupted.
Different devices and services are assigned different priorities. For instance, a disk read/write operation might be high priority because delaying it could slow down the entire system, while updating a mouse cursor position might be lower priority.
To further refine this process, modern systems use features like vectored interrupts, which quickly direct the host to the appropriate handler for an interrupt, avoiding the need to check all possible sources. This is like having a personalized notification sound for each app on your phone, so you know instantly whether an alert is for an email, a message, or a calendar event.
Moreover, to prevent a flood of interrupts from overwhelming the system, devices can be set up to raise interrupts only after completing a batch of tasks, or interrupts can be prioritized so that more critical tasks can interrupt less critical ones.
In essence, the interplay of handshaking, polling, interrupts, and priority systems allows computers to communicate efficiently with a wide array of devices, handling multiple tasks simultaneously without compromising responsiveness or performance. It's a complex dance of signals and responses that keeps our modern digital world running smoothly, ensuring that every click, keystroke, and data transfer happens almost instantaneously and reliably.
Polling and interrupts are two fundamental mechanisms for handling I/O (Input/Output) operations in computer systems, allowing the CPU to communicate with peripheral devices. Each method has its advantages and disadvantages, and the choice between them depends on the specific requirements of the application or system. Following is a breakdown of the pros and cons of each method and insights into when to use one over the other.
Polling
Pros:
Simplicity: Polling is straightforward to implement. It involves the CPU continuously checking the status of a device to see if it needs attention, which is a simple loop of instructions.
Predictability: Since the CPU actively checks the status of devices at regular intervals, the behavior and timing of polling-based systems are predictable, which can be advantageous in certain real-time applications.
Cons:
CPU Inefficiency: Polling can lead to wasteful use of CPU resources, as the CPU spends time checking devices that do not require attention, potentially impacting the performance of other tasks.
Increased Latency: In systems that rely heavily on polling, there can be increased latency in handling I/O operations because a device must wait until the next poll to be serviced.
Difficulty Scaling: As the number of devices increases, the inefficiency and management complexity of polling-based systems also increase, making it less suitable for handling many devices.
When to Use Polling:
When dealing with a small number of devices that require frequent and quick checks.
In real-time systems where the predictability of response times is more critical than overall system efficiency.
For simple I/O operations where the overhead of handling interrupts would not justify their use.
Interrupts
Pros:
Efficiency: Interrupts allow the CPU to utilize its time effectively, as it only deals with devices when they indicate they need attention. This mechanism frees the CPU to perform other tasks or enter a low-power state when idle.
Responsiveness: Systems using interrupts can respond more quickly to I/O requests since the device notifies the CPU immediately when it requires service.
Scalability: Interrupt-driven systems can handle many devices efficiently because the CPU is only called upon when necessary, making this approach more scalable than polling.
Cons:
Complexity: Implementing interrupt-driven systems can be more complex than polling due to the need for interrupt handlers and managing the interrupt enabling/disabling states.
Priority Inversion: Without careful management, lower-priority tasks may block higher-priority tasks, leading to priority inversion issues.
Potential for Overhead: In systems with very high rates of interrupts, the overhead of handling these interrupts can impact performance, especially if the interrupts are frequent but require minimal processing.
When to Use Interrupts:
In applications where efficiency and responsiveness are critical, and the CPU should remain free for other tasks when not servicing I/O requests.
When the system has many peripheral devices, making polling impractical due to the CPU overhead.
In complex systems where minimizing latency in response to external events is crucial.
In computing, especially with devices that perform large data transfers like disk drives, using the main CPU to constantly monitor the transfer status and move data byte by byte—a method known as Programmed I/O (PIO)—can be highly inefficient. It's akin to asking a busy office manager to personally deliver every single document by hand; it gets the job done but at the expense of more critical tasks. To address this inefficiency, many computer systems use a special component called a Direct Memory Access (DMA) controller.
The DMA controller is designed to handle data transfers directly between memory and the device, bypassing the CPU for the bulk of the work. Here's a simplified step-by-step of how it operates:
Setting Up: The CPU initiates the process by writing a DMA command block into memory. This block contains the details of the transfer: where the data is coming from, where it's going to, and how much data there is.
Transferring Control: The CPU then informs the DMA controller about this command block and proceeds with other tasks, effectively delegating the data transfer responsibility.
Direct Transfer: The DMA controller communicates directly with both the memory and the device to transfer the data, using a pair of signals (DMA-request and DMA-acknowledge) for coordination. This allows data to move to its destination without CPU intervention.
Finishing Up: Once the transfer is complete, the DMA controller sends an interrupt to the CPU, signaling that the task is done and the CPU can continue its involvement if necessary.
During this process, there are moments when the DMA controller needs exclusive access to the memory bus, temporarily blocking the CPU from accessing main memory. This situation, known as "cycle stealing," can slightly slow down the CPU but is generally a worthwhile trade-off for the overall efficiency gain.
DMA and System Architecture
Different systems implement DMA differently. Some use physical memory addresses directly, while others use virtual addresses that are then translated to physical ones—this latter method allows for even more sophisticated operations like transferring data between two devices without CPU or main memory involvement.
Security and Control
Modern operating systems typically restrict direct device access to prevent security breaches and system crashes. Only privileged processes are allowed to initiate low-level operations like DMA transfers. This protective approach contrasts with less secure environments where processes might directly access hardware, trading off security for performance.
The DMA approach is like having a specialized courier service within the office that handles all document deliveries: it frees up the manager (CPU) to focus on decision-making and coordination, improves efficiency, and enhances the overall workflow (system performance). While this introduces some complexities, such as security management and occasional access contention, the benefits of DMA in terms of freeing up CPU resources and speeding up data transfers make it a crucial feature in modern computing systems.
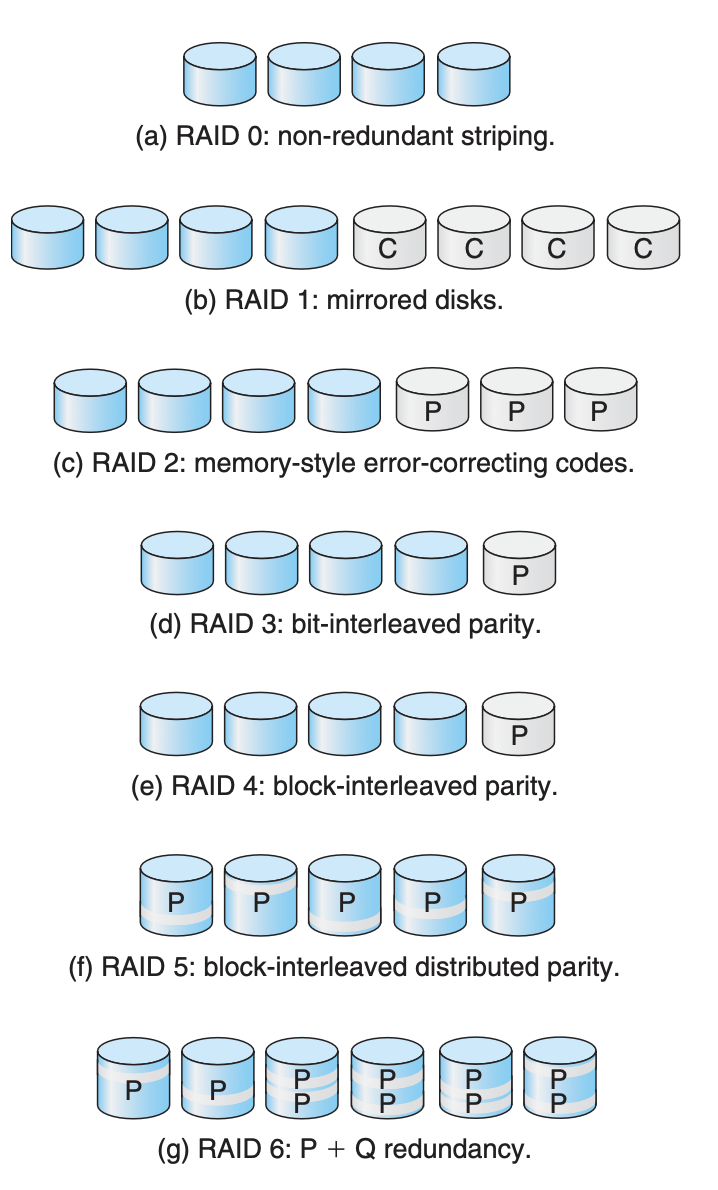
RAID (Redundant Array of Independent Disks) is a data storage virtualization technology that combines multiple physical disk drive components into a single logical unit for the purposes of data redundancy, performance improvement, or both. RAID levels vary in data distribution techniques, with each offering a different balance of performance, data availability, and storage capacity. Let's explore each of the commonly used RAID levels in detail:
RAID 0 (Striping)
Description: Splits data evenly across two or more disks with no redundancy. It improves performance by allowing I/O operations to overlap in a balanced way.
Advantages: Highest performance level of all RAIDs due to parallel operations.
Disadvantages: No redundancy; if one drive fails, all data in the array is lost.
Use Cases: Situations where speed is paramount and data loss is not a critical concern, such as in a non-critical cache.
RAID 1 (Mirroring)
Description: Copies identical data onto two or more drives, creating a "mirror." It does not improve write speed but can improve read speed in some implementations.
Advantages: Provides redundancy. If one drive fails, data is still accessible from another.
Disadvantages: High cost due to the requirement of double the storage capacity for protection.
Use Cases: Critical applications where data redundancy is more important than storage efficiency, like key database systems.
RAID 2 (Bit-Level Striping with ECC)
Description: Rarely used, it stripes data at the bit level rather than the block level and uses Hamming Code for error correction.
Advantages: Error correction capability.
Disadvantages: Very high overhead and complexity; made obsolete by later RAID levels.
Use Cases: Historically significant but not used in contemporary systems.
RAID 3 (Byte-Level Striping with Dedicated Parity)
Description: Similar to RAID 0, but with a dedicated parity disk for error correction, allowing for data recovery in the event of a disk failure.
Advantages: Can recover data if a single drive fails.
Disadvantages: Write operations require access to the parity drive, causing a bottleneck.
Use Cases: Applications requiring high read and write throughput for large files, like video production.
RAID 4 (Block-Level Striping with Dedicated Parity)
Description: Stripes data at the block level with a dedicated parity disk.
Advantages: Allows for the reconstruction of data from the parity information if a single disk fails.
Disadvantages: Similar to RAID 3, the parity disk can become a bottleneck.
Use Cases: Not commonly used; superseded by RAID 5.
RAID 5 (Block-Level Striping with Distributed Parity)
Description: Distributes parity along with the data across all drives in the array, requiring all drives but one to be present to operate.
Advantages: Good balance of performance, storage efficiency, and data security.
Disadvantages: Disk failure requires significant time and system resources to rebuild data.
Use Cases: Widely used in business and enterprise environments where balance is necessary.
RAID 6 (Block-Level Striping with Double Distributed Parity)
Description: Extends RAID 5 by adding another parity block, thus allowing the array to withstand the loss of up to two disks.
Advantages: Greater fault tolerance than RAID 5.
Disadvantages: Additional parity causes overhead, reducing usable capacity and write performance.
Use Cases: Environments where data availability and fault tolerance are critical, such as in financial data centers.
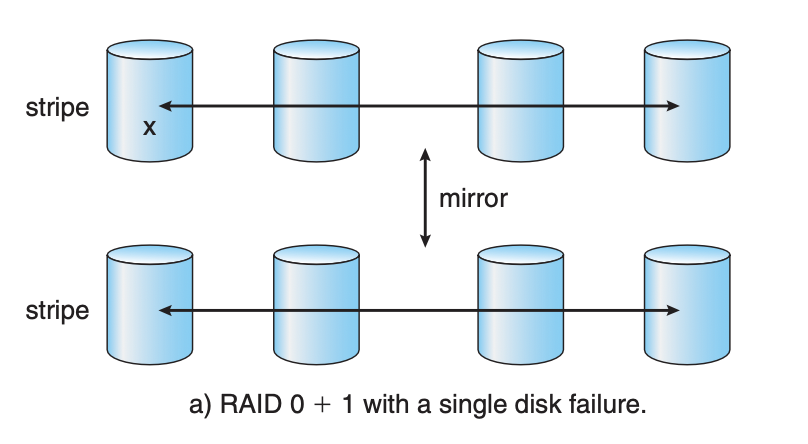
RAID 10 (1+0): Mirroring and Striping
Description: Combines the features of RAID 1 and RAID 0, providing both redundancy and improved performance by mirroring a set of striped disks.
Advantages: High performance and redundancy.
Disadvantages: High cost due to the requirement for at least four disks and only using half of the total capacity for storage.
Use Cases: High-performance applications requiring maximum uptime and data integrity, like critical database servers.
Each RAID level offers a compromise between performance, cost, and data protection. The choice of RAID configuration depends on the specific requirements of the application, including the need for data redundancy, performance, and storage capacity.