Introduction to Trees
I am Jyotiprakash, a deeply driven computer systems engineer, software developer, teacher, and philosopher. With a decade of professional experience, I have contributed to various cutting-edge software products in network security, mobile apps, and healthcare software at renowned companies like Oracle, Yahoo, and Epic. My academic journey has taken me to prestigious institutions such as the University of Wisconsin-Madison and BITS Pilani in India, where I consistently ranked among the top of my class.
At my core, I am a computer enthusiast with a profound interest in understanding the intricacies of computer programming. My skills are not limited to application programming in Java; I have also delved deeply into computer hardware, learning about various architectures, low-level assembly programming, Linux kernel implementation, and writing device drivers. The contributions of Linus Torvalds, Ken Thompson, and Dennis Ritchie—who revolutionized the computer industry—inspire me. I believe that real contributions to computer science are made by mastering all levels of abstraction and understanding systems inside out.
In addition to my professional pursuits, I am passionate about teaching and sharing knowledge. I have spent two years as a teaching assistant at UW Madison, where I taught complex concepts in operating systems, computer graphics, and data structures to both graduate and undergraduate students. Currently, I am an assistant professor at KIIT, Bhubaneswar, where I continue to teach computer science to undergraduate and graduate students. I am also working on writing a few free books on systems programming, as I believe in freely sharing knowledge to empower others.
In computer science, trees are a fundamental non-linear data structure composed of nodes connected by edges. A tree is a hierarchical model that represents a collection of elements, each of which can have a number of children but only one parent (except the root, which has no parent). Trees provide an efficient means of organizing and storing data, and they are heavily used in various algorithms and system designs due to their inherent hierarchical nature.
Key characteristics of a tree:
Root Node: The topmost node in the tree, which acts as the starting point for traversing the entire tree. Every tree has exactly one root node.
Nodes: The elements of the tree. A node can store data and have zero or more children.
Edges: The connections between nodes that define the relationships (parent-child) in the tree.
Leaf Nodes: Nodes that do not have any children. They are located at the bottom of the tree.
Height: The height of a tree is defined as the length of the longest path from the root to a leaf.
Subtree: A subtree is any node in the tree along with all of its descendants.
Depth: The depth of a node is the number of edges from the root to the node.
A classic example of a tree in everyday life is the directory structure of a file system, where folders act as nodes, and the parent-child relationship represents the folder hierarchy.
Importance of Trees in Computer Science
Trees are important in computer science due to their flexibility and efficiency in organizing data in a hierarchical structure. They are essential for solving problems where a relationship between entities is best represented in a hierarchical manner (e.g., organization charts, genealogy trees, database indexing, etc.). Some common applications include:
File Systems: Trees are used to represent hierarchical directory structures where each directory (node) can contain files or other directories.
Searching and Sorting: Binary Search Trees (BST) enable efficient searching, insertion, and deletion of elements in O(log n) time in a balanced tree.
Expression Parsing: Trees (e.g., expression trees, syntax trees) are used to represent and evaluate expressions in compilers.
Decision-making Processes: Decision trees help in making decisions based on a set of conditions (commonly used in AI and machine learning).
Networking: Spanning trees are used in routing algorithms to ensure all nodes are connected without creating loops.
Comparison Between Trees and Other Data Structures
While trees share some similarities with other data structures like arrays and linked lists, their structure and use cases are distinct. Here's a comparison to highlight the differences:
Trees vs. Arrays
Structure: Arrays are a linear data structure where elements are stored in contiguous memory locations. Trees, on the other hand, are non-linear, hierarchical structures where elements (nodes) are connected through parent-child relationships.
Access Time: Arrays provide constant-time access (O(1)) for indexing elements if the index is known. However, trees require traversal (e.g., in-order, pre-order) to access elements, which can take O(log n) time for balanced trees and O(n) in the worst case for unbalanced trees.
Dynamic Nature: Trees can dynamically grow or shrink as elements are inserted or deleted, making them more flexible. Arrays, being a static data structure, require resizing if the capacity limit is reached, which can be expensive.
Use Case: Arrays are ideal for sequential data or when random access is required. Trees, however, are more suited for hierarchical data and scenarios that require dynamic organization, such as implementing priority queues or managing hierarchical data (e.g., file systems, organizational charts).
Trees vs. Linked Lists
Structure: A linked list is also a linear structure where each node points to the next node (in a singly linked list) or both the previous and the next node (in a doubly linked list). Trees, on the other hand, have a hierarchical structure where each node can point to multiple child nodes.
Search and Insertion: Linked lists require O(n) time for search, insertion, and deletion because nodes are accessed sequentially. Trees, particularly balanced binary trees, offer O(log n) time complexity for search, insertion, and deletion, making them more efficient in many cases.
Parent-Child Relationships: Linked lists do not exhibit a parent-child relationship between nodes, while trees inherently do. This parent-child relationship makes trees suitable for tasks like hierarchical data representation or recursive algorithms (e.g., traversal).
Use Case: Linked lists are used when elements need to be added or removed frequently at the beginning or the end of a collection. Trees are better for organizing data that has a natural hierarchy or where frequent searching is needed (e.g., search engines, databases).
In a tree data structure, several terms describe the relationship between different parts of the tree. Understanding these terms is critical for navigating, implementing, and using tree structures efficiently.
Basic Tree Terminology
Root: The topmost node in the tree. It serves as the starting point for any traversal.
Node: Each element in a tree is called a node. A node contains data and may have links to child nodes.
Leaf: A node with no children is called a leaf node.
Parent: A node that has one or more children is called the parent of those nodes.
Child: Nodes that are directly connected to another node are called children of that node.
Siblings: Nodes that share the same parent are called siblings.
Height: The height of a node is the number of edges on the longest path from that node to a leaf. The height of a tree is the height of the root node.
Depth: The depth of a node is the number of edges from the root node to the node.
Subtree: Any node and all its descendants form a subtree.
Degree: The number of children a node has is called its degree.
1 (Root)
/ \
2 3 (Children of 1, Siblings)
/ \ / \
4 5 6 7 (Children of 2 and 3, Leaves: 4, 5, 6, 7)
Root: 1
Children of 1: 2, 3
Siblings: 2 and 3; 4 and 5; 6 and 7
Leaf Nodes: 4, 5, 6, 7 (They have no children)
Height of tree: 2 (Longest path from root to leaf)
Depth of node 4: 2 (2 edges from root)
Example: Tree Terminology in C Code
We can represent this tree structure in C using a simple struct for a node and pointers to its left and right children (for binary trees). Here's how this can be done:
#include <stdio.h>
#include <stdlib.h>
// Define the structure for a tree node
struct Node {
int data;
struct Node* left;
struct Node* right;
};
// Function to create a new node
struct Node* newNode(int data) {
struct Node* node = (struct Node*)malloc(sizeof(struct Node));
node->data = data;
node->left = NULL;
node->right = NULL;
return node;
}
// Function to calculate the height of a tree
int height(struct Node* node) {
if (node == NULL)
return -1; // Height of an empty tree is -1
else {
int leftHeight = height(node->left);
int rightHeight = height(node->right);
// Height is the maximum of leftHeight or rightHeight plus 1
return (leftHeight > rightHeight ? leftHeight : rightHeight) + 1;
}
}
// Function to print the depth of a node
void printDepth(struct Node* node, int level) {
if (node != NULL) {
printf("Node %d is at depth %d\n", node->data, level);
printDepth(node->left, level + 1);
printDepth(node->right, level + 1);
}
}
int main() {
// Constructing the tree from the ASCII art
struct Node* root = newNode(1);
root->left = newNode(2);
root->right = newNode(3);
root->left->left = newNode(4);
root->left->right = newNode(5);
root->right->left = newNode(6);
root->right->right = newNode(7);
// Height of the tree
printf("Height of the tree: %d\n", height(root));
// Depth of each node
printDepth(root, 0);
return 0;
}
Explanation
Root: In the code, the node
rootis the root of the tree (1in the example).Node: Every element in the tree (e.g.,
root->left,root->right) is a node.Leaf Nodes: The nodes
4, 5, 6, 7are leaf nodes since theirleftandrightpointers areNULL.Parent: Node
1is the parent of nodes2and3. Similarly, node2is the parent of nodes4and5.Child: Node
2is a child of node1. Nodes4and5are children of node2.Siblings: Nodes
2and3are siblings because they share the same parent (node1). Similarly, nodes4and5are siblings.Height: The height of the tree is calculated by the
height()function, which finds the longest path from the root node to a leaf node. In this case, the height of the tree is 2.Depth: The
printDepth()function prints the depth of each node. The depth of a node is the number of edges from the root to the node. For example, node4is at depth 2 because it takes two steps from the root (1 → 2 → 4).
Output
Height of the tree: 2
Node 1 is at depth 0
Node 2 is at depth 1
Node 4 is at depth 2
Node 5 is at depth 2
Node 3 is at depth 1
Node 6 is at depth 2
Node 7 is at depth 2
Additional Terminology
Subtree: Every node in a tree is a root of its subtree. For example, the subtree rooted at node
2contains nodes2,4, and5.Degree of a node: Node
1has a degree of 2 because it has two children (2 and 3). Nodes4,5,6, and7each have a degree of 0 because they are leaf nodes with no children.
Binary Trees
A binary tree is a hierarchical data structure in which each node has at most two children, commonly referred to as the left child and the right child. These trees are widely used in various applications like searching, sorting, and expression evaluation due to their efficient structure and traversal techniques.
A binary tree can be represented using the following properties:
Each node contains a value or data.
Each node has at most two child nodes (left and right).
The tree has a root node from which all other nodes branch out.
Binary trees can be implemented in C by using a structure that defines a node and pointers to its left and right children.
Basic Binary Tree Structure in C
#include <stdio.h>
#include <stdlib.h>
// Structure of a Binary Tree Node
struct Node {
int data;
struct Node* left;
struct Node* right;
};
// Function to create a new node
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
Here’s a simple example of a binary tree:
1
/ \
2 3
/ \ \
4 5 6
This structure can be represented in C as:
int main() {
struct Node* root = createNode(1);
root->left = createNode(2);
root->right = createNode(3);
root->left->left = createNode(4);
root->left->right = createNode(5);
root->right->right = createNode(6);
return 0;
}
Distinction Between Full, Complete, and Extended Binary Trees
1. Full Binary Tree
A full binary tree is a tree in which every node has either 0 or 2 children. No node in a full binary tree has only one child. This strict structure ensures that each internal node has exactly two children.
1
/ \
2 3
/ \
4 5
In this tree:
- Every node either has 0 children (nodes 4 and 5) or 2 children (node 1 and node 2).
2. Complete Binary Tree
A complete binary tree is a binary tree in which all levels, except possibly the last, are completely filled, and all nodes in the last level are as far left as possible. This structure ensures the tree remains balanced and occupies minimal space.
1
/ \
2 3
/ \ /
4 5 6
In this tree:
The last level (containing nodes 4, 5, and 6) is filled from the left.
The second level is completely filled.
3. Extended Binary Tree (or Strict Binary Tree)
An extended binary tree is a variation where every node has either 0 or exactly 2 children. In extended trees, null links (where children do not exist) are replaced by special nodes (external nodes) to maintain uniformity.
1
/ \
2 3
/ \ \
* 5 *
In this tree:
Every internal node (1, 2, 3) either has 0 or 2 children.
The null links are replaced by the special nodes (represented as
*).
Structural Properties of Binary Trees
Maximum Number of Nodes:
- A binary tree of height ( h ) has at most ( 2^{h+1} - 1 ) nodes. For example, a binary tree with height 2 can have at most ( 2^{2+1} - 1 = 7 ) nodes.
Minimum Height:
- The minimum height of a binary tree with ( n ) nodes is ( \log_2(n+1) - 1 ).
Perfect Binary Tree:
- A perfect binary tree is both full and complete. All internal nodes have exactly two children, and all leaf nodes are at the same level.
1
/ \
2 3
/ \ / \
4 5 6 7
This tree has:
( 2^3 - 1 = 7 ) nodes.
Height of the tree = 2.
All leaf nodes (4, 5, 6, 7) are at the same level.
Summary of Binary Tree Types
| Type | Definition |
| Full Binary Tree | Every node has 0 or 2 children, no nodes have only 1 child. |
| Complete Binary Tree | All levels except the last are fully filled; the last level is filled from left to right. |
| Extended Binary Tree | Special binary tree where every node has 0 or exactly 2 children; null links replaced by special nodes. |
| Perfect Binary Tree | A binary tree where all internal nodes have 2 children, and all leaves are at the same level. |
Binary Tree Traversal Algorithms
Traversal in a binary tree refers to visiting each node in a specific order. There are several methods to traverse a binary tree, each serving different use cases. The most common traversal techniques are in-order, pre-order, post-order, and level-order.
1. In-Order Traversal
Algorithm: Traverse the left subtree, visit the root, then traverse the right subtree.
Use Case: In-order traversal is primarily used to retrieve data from a Binary Search Tree (BST) in sorted order.
In-Order Traversal Example
Consider the following binary tree:
1
/ \
2 3
/ \
4 5
The in-order traversal of this tree would be:
4, 2, 5, 1, 3
In-Order Traversal: Recursive Implementation (C)
void inOrder(struct Node* node) {
if (node == NULL)
return;
inOrder(node->left); // Visit left subtree
printf("%d ", node->data); // Print node data
inOrder(node->right); // Visit right subtree
}
In-Order Traversal: Iterative Implementation (C)
#include <stdbool.h>
void inOrderIterative(struct Node* root) {
struct Node* stack[100];
int top = -1;
struct Node* curr = root;
while (curr != NULL || top >= 0) {
// Reach the leftmost node
while (curr != NULL) {
stack[++top] = curr;
curr = curr->left;
}
// Current node must be NULL at this point
curr = stack[top--];
printf("%d ", curr->data);
// Now visit the right subtree
curr = curr->right;
}
}
2. Pre-Order Traversal
Algorithm: Visit the root, traverse the left subtree, then traverse the right subtree.
Use Case: Pre-order traversal is used to create a copy of the tree or to serialize the tree structure for later reconstruction. It's also useful in prefix expression evaluation.
Pre-Order Traversal Example
For the same tree:
1
/ \
2 3
/ \
4 5
The pre-order traversal would be:
1, 2, 4, 5, 3
Pre-Order Traversal: Recursive Implementation (C)
void preOrder(struct Node* node) {
if (node == NULL)
return;
printf("%d ", node->data); // Print node data
preOrder(node->left); // Visit left subtree
preOrder(node->right); // Visit right subtree
}
Pre-Order Traversal: Iterative Implementation (C)
void preOrderIterative(struct Node* root) {
if (root == NULL)
return;
struct Node* stack[100];
int top = -1;
stack[++top] = root;
while (top >= 0) {
struct Node* curr = stack[top--];
printf("%d ", curr->data);
// Push right child first, so left child is processed first
if (curr->right)
stack[++top] = curr->right;
if (curr->left)
stack[++top] = curr->left;
}
}
3. Post-Order Traversal
Algorithm: Traverse the left subtree, traverse the right subtree, then visit the root.
Use Case: Post-order traversal is used for deleting the tree or when operations need to be performed on children before the parent. It is also useful in postfix expression evaluation.
Post-Order Traversal Example
For the same tree:
1
/ \
2 3
/ \
4 5
The post-order traversal would be:
4, 5, 2, 3, 1
Post-Order Traversal: Recursive Implementation (C)
void postOrder(struct Node* node) {
if (node == NULL)
return;
postOrder(node->left); // Visit left subtree
postOrder(node->right); // Visit right subtree
printf("%d ", node->data); // Print node data
}
Post-Order Traversal: Iterative Implementation (C)
void postOrderIterative(struct Node* root) {
struct Node* stack1[100];
struct Node* stack2[100];
int top1 = -1, top2 = -1;
if (root == NULL)
return;
stack1[++top1] = root;
while (top1 >= 0) {
struct Node* curr = stack1[top1--];
stack2[++top2] = curr;
if (curr->left)
stack1[++top1] = curr->left;
if (curr->right)
stack1[++top1] = curr->right;
}
// Print from the second stack
while (top2 >= 0)
printf("%d ", stack2[top2--]->data);
}
4. Level-Order Traversal
Algorithm: Visit nodes level by level from top to bottom, left to right.
Use Case: Level-order traversal is used for breadth-first search (BFS) in trees, or when you need to process nodes in a breadth-first manner (e.g., in shortest path algorithms, or when calculating depth in some applications).
Level-Order Traversal Example
For the same tree:
1
/ \
2 3
/ \
4 5
The level-order traversal would be:
1, 2, 3, 4, 5
Level-Order Traversal: Iterative Implementation (C)
This traversal uses a queue to visit nodes level by level.
#include <stdbool.h>
#define MAX_QUEUE_SIZE 100
// Queue structure
struct Node* queue[MAX_QUEUE_SIZE];
int front = 0, rear = 0;
bool isQueueEmpty() {
return front == rear;
}
void enqueue(struct Node* node) {
queue[rear++] = node;
}
struct Node* dequeue() {
return queue[front++];
}
void levelOrder(struct Node* root) {
if (root == NULL)
return;
enqueue(root);
while (!isQueueEmpty()) {
struct Node* curr = dequeue();
printf("%d ", curr->data);
if (curr->left)
enqueue(curr->left);
if (curr->right)
enqueue(curr->right);
}
}
Use Cases for Each Traversal Method
| Traversal Method | Use Case |
| In-Order | Retrieve elements from a binary search tree (BST) in sorted order. |
| Pre-Order | Create a copy of the tree, serialize the tree, or prefix expression evaluation. |
| Post-Order | Delete the entire tree, postfix expression evaluation. |
| Level-Order | Breadth-first search (BFS), shortest path algorithms, calculating depth. |
Expression Trees
Overview of Expression Trees
An expression tree is a binary tree used to represent arithmetic expressions. In an expression tree:
Leaf nodes represent operands (constants or variables), such as numbers or variables like
x,y, etc.Internal nodes represent operators, such as
+,-,*,/, etc.
The structure of the tree reflects the order of operations in the expression. Each internal node of the tree represents an operator applied to the operands or sub-expressions represented by its child nodes.
Expression trees are extremely useful for:
Evaluating expressions: The tree structure naturally respects operator precedence.
Transforming expressions: Such as converting between infix, prefix (Polish notation), and postfix (Reverse Polish Notation) expressions.
Simplifying expressions: By applying algebraic rules.
Compiling expressions: When generating machine code in compilers.
Construction of Expression Trees
Consider the arithmetic expression:
[ (3 + 4) * (5 - 2) ]
The expression tree for this expression would look like:
*
/ \
+ -
/ \ / \
3 4 5 2
The root of the tree is the
*operator because multiplication occurs after the addition and subtraction in the parentheses.The left subtree represents the expression
3 + 4.The right subtree represents the expression
5 - 2.
C Representation of Expression Trees
We can use a struct in C to represent each node in the tree, where the data can either be an operator or an operand, and each node points to two children (left and right).
#include <stdio.h>
#include <stdlib.h>
// Define structure for a node
struct Node {
char data; // data can be operator (+, -, *, /) or operand (number)
struct Node* left;
struct Node* right;
};
// Function to create a new node
struct Node* createNode(char data) {
struct Node* node = (struct Node*)malloc(sizeof(struct Node));
node->data = data;
node->left = NULL;
node->right = NULL;
return node;
}
Constructing an Expression Tree
To construct an expression tree from a postfix (Reverse Polish Notation) expression is one of the common approaches. In postfix notation, the operator follows the operands, so it is easier to construct the tree.
Let's construct an expression tree for the postfix expression:
3 4 + 5 2 - *
This postfix notation corresponds to the infix expression:
(3 + 4) * (5 - 2)
Algorithm for constructing an expression tree from a postfix expression:
Create an empty stack.
Iterate over the postfix expression from left to right.
If the character is an operand, push it onto the stack.
If the character is an operator:
Pop the top two elements from the stack (these will be the operator's operands).
Create a new tree node with this operator.
Set the popped elements as the left and right children of the operator node.
Push the operator node back onto the stack.
When finished, the only element in the stack will be the root of the expression tree.
#include <ctype.h> // For checking if a character is a digit
// Structure for a stack of tree nodes
struct Stack {
int top;
struct Node* items[100];
};
// Initialize stack
struct Stack* createStack() {
struct Stack* stack = (struct Stack*)malloc(sizeof(struct Stack));
stack->top = -1;
return stack;
}
// Push to stack
void push(struct Stack* stack, struct Node* node) {
stack->items[++stack->top] = node;
}
// Pop from stack
struct Node* pop(struct Stack* stack) {
return stack->items[stack->top--];
}
// Function to construct expression tree from a postfix expression
struct Node* constructTree(char postfix[]) {
struct Stack* stack = createStack();
struct Node *t, *t1, *t2;
// Traverse the postfix expression
for (int i = 0; postfix[i] != '\0'; i++) {
// If operand, create a new node and push it to stack
if (isdigit(postfix[i])) {
t = createNode(postfix[i]);
push(stack, t);
}
// If operator, pop two nodes and make them children of the operator node
else {
t = createNode(postfix[i]);
// Pop two nodes
t1 = pop(stack); // Right child
t2 = pop(stack); // Left child
// Make them children
t->right = t1;
t->left = t2;
// Push the current node back to stack
push(stack, t);
}
}
// The only element left in the stack is the root of the expression tree
t = pop(stack);
return t;
}
Evaluating an Expression Tree
Once the expression tree is constructed, it can be evaluated by performing a post-order traversal (left subtree, right subtree, root). For each internal node (operator), we perform the operation on its children and return the result.
Here’s the evaluation algorithm:
// Function to evaluate the expression tree
int evaluate(struct Node* root) {
// Base case: if the node is a leaf (operand), return its value
if (root->left == NULL && root->right == NULL)
return root->data - '0'; // Convert character digit to int
// Recursively evaluate left and right subtrees
int leftEval = evaluate(root->left);
int rightEval = evaluate(root->right);
// Apply the operator
if (root->data == '+')
return leftEval + rightEval;
if (root->data == '-')
return leftEval - rightEval;
if (root->data == '*')
return leftEval * rightEval;
if (root->data == '/')
return leftEval / rightEval;
return 0;
}
int main() {
char postfix[] = "34+52-*"; // Postfix expression
struct Node* root = constructTree(postfix);
printf("Result of expression evaluation: %d\n", evaluate(root)); // Output: 21
return 0;
}
Example: Evaluating (3 + 4) * (5 - 2)
For the postfix expression "34+52-*":
Step 1: Create nodes for
3,4,+,5,2,-,*.Step 2: Attach nodes based on the postfix evaluation algorithm.
Step 3: Traverse the tree in post-order and apply the operators.
The final result for the expression (3 + 4) * (5 - 2) is 21.
Infix, Prefix, and Postfix Notations
An expression tree allows us to easily convert between infix, prefix, and postfix notations:
Infix: Traverse the tree in in-order (left subtree, root, right subtree).
Prefix: Traverse the tree in pre-order (root, left subtree, right subtree).
Postfix: Traverse the tree in post-order (left subtree, right subtree, root).
Infix Notation from Tree
The infix notation of the above example (with parentheses to clarify order of operations) is:
(3 + 4) * (5 - 2)
Prefix Notation from Tree
The prefix notation is:
* + 3 4 - 5 2
Postfix Notation from Tree
The postfix notation is:
3 4 + 5 2 - *
Representation of Binary Trees
Linked Representation of Binary Trees
In the linked representation, each node in the tree is represented by a structure (in C, typically a struct), which contains:
Data: The value stored in the node (which can be any type).
Left pointer: A pointer to the left child node.
Right pointer: A pointer to the right child node.
Structure of a Node in C
#include <stdio.h>
#include <stdlib.h>
// Define structure for a binary tree node
struct Node {
int data; // Data in the node
struct Node* left; // Pointer to the left child
struct Node* right; // Pointer to the right child
};
// Function to create a new node
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
Advantages of Linked Representation:
Dynamic: The binary tree size is not fixed and can grow or shrink dynamically as nodes are added or removed.
Memory Efficient: Memory is allocated only when a new node is created, making it suitable for sparse trees.
Supports all types of trees: Can represent all kinds of binary trees (full, complete, sparse, etc.).
Use Cases for Linked Representation:
Suitable for trees where the structure can frequently change (e.g., trees used in search operations, AVL trees, expression trees).
Works well when the tree is sparse (i.e., many nodes do not have two children).
Example Tree (Linked Representation):
Let’s take the following binary tree:
1
/ \
2 3
/ \
4 5
C Code to Create and Represent the Above Tree:
int main() {
// Create the root node
struct Node* root = createNode(1);
// Create the left and right children
root->left = createNode(2);
root->right = createNode(3);
// Create further children
root->left->left = createNode(4);
root->left->right = createNode(5);
return 0;
}
Array Representation of Binary Trees
In the array representation, a binary tree is stored in a single array, where the position of each element in the array corresponds to its position in the tree. This approach works well for complete or perfect binary trees because of the regular structure.
For a complete binary tree, the following relationships hold for a node at index i (0-based indexing):
Parent of node
i: The parent is located at index \(\left\lfloor \frac{i-1}{2} \right\rfloor\).Left child of node
i: The left child is located at index (2i + 1).Right child of node
i: The right child is located at index (2i + 2).
Example: Array Representation of a Complete Binary Tree
Consider the following complete binary tree:
1
/ \
2 3
/ \ \
4 5 6
This tree can be stored in an array as:
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Value | 1 | 2 | 3 | 4 | 5 | 6 |
The root node (1) is at index 0.
The left child of 1 (node 2) is at index 1, and the right child (node 3) is at index 2.
The left child of 2 (node 4) is at index 3, and the right child (node 5) is at index 4.
The right child of 3 (node 6) is at index 5.
Array Representation Formula:
Parent of a node at index (i): \(\left\lfloor \frac{i-1}{2} \right\rfloor\)
Left child of a node at index (i): (2i + 1)
Right child of a node at index (i): (2i + 2)
C Code for Array Representation:
#include <stdio.h>
int main() {
// Array representation of the binary tree
int tree[7] = {1, 2, 3, 4, 5, 6};
// Printing nodes
printf("Root: %d\n", tree[0]);
printf("Left child of root: %d\n", tree[1]);
printf("Right child of root: %d\n", tree[2]);
printf("Left child of node 2: %d\n", tree[3]);
printf("Right child of node 2: %d\n", tree[4]);
printf("Right child of node 3: %d\n", tree[5]);
return 0;
}
Advantages of Array Representation:
Fast Access: Accessing any node by its index is O(1), making it ideal for complete binary trees.
Efficient for Complete Trees: For complete or perfect binary trees, the array representation saves space since there are no gaps between elements.
Disadvantages of Array Representation:
Wasted Space for Sparse Trees: For sparse trees, where many nodes do not have two children, the array representation wastes space because there are gaps (empty slots) in the array.
Static Size: The size of the tree (array) must be known beforehand. If the tree grows beyond the initially allocated size, resizing the array can be expensive.
Use Cases for Array Representation:
Suitable for complete binary trees such as heaps (e.g., binary heap) used in priority queues.
Suitable for perfect binary trees where there is no unused space in the array.
Comparison Between Linked and Array Representations
| Criteria | Linked Representation | Array Representation |
| Memory Usage | Dynamic memory usage (no unused space). | Efficient for complete binary trees but wastes space for sparse trees. |
| Flexibility | Dynamic structure: can grow or shrink easily. | Fixed size; resizing is expensive. |
| Ease of Access | Accessing nodes requires traversal (O(log n) or O(n)). | Constant-time access to any node (O(1)). |
| Efficient for | Suitable for all types of binary trees (especially sparse or incomplete trees). | Best suited for complete or perfect binary trees. |
| Node Relationships | Pointers explicitly define relationships. | Parent-child relationships are implicit using index arithmetic. |
| Space Efficiency | Memory is allocated only for existing nodes. | Wastes space if the tree is not complete (empty slots for missing nodes). |
| Implementation Complexity | More complex to implement due to dynamic memory management. | Simple to implement for complete binary trees. |
Binary Search Trees (BST)
A Binary Search Tree (BST) is a special type of binary tree that follows a specific ordering property. This ordering allows for efficient searching, insertion, and deletion operations. BSTs are widely used in computer science for tasks that require dynamic data storage with efficient access.
Properties and Structure of Binary Search Trees
The Binary Search Tree (BST) has the following key properties:
Binary Tree Structure: Each node has at most two children, referred to as the left and right children.
Ordering Property: For every node
Nin the tree:All values in the left subtree of
Nare less than the value ofN.All values in the right subtree of
Nare greater than the value ofN.
Because of this ordering property, the BST supports efficient searching, insertion, and deletion operations.
BST Example
Here is an example of a Binary Search Tree (BST):
8
/ \
3 10
/ \ \
1 6 14
/ \ /
4 7 13
The root node is
8.All nodes in the left subtree of
8have values less than8(e.g.,3,1,6, etc.).All nodes in the right subtree of
8have values greater than8(e.g.,10,14,13).
Operations on Binary Search Trees
The fundamental operations on a binary search tree include searching, insertion, and deletion. Let's take a closer look at each operation and their respective algorithms.
Search Operation in BST
The search operation in a BST takes advantage of the tree's ordering property. Starting from the root, the algorithm compares the target value with the current node's value:
If the target value is less than the current node, move to the left subtree.
If the target value is greater than the current node, move to the right subtree.
If the target value matches the current node's value, the value is found.
This recursive process continues until the value is found or a leaf node is reached, indicating that the value does not exist in the tree.
C Code for Searching in a BST
#include <stdio.h>
#include <stdlib.h>
// Define structure for a binary search tree node
struct Node {
int data;
struct Node* left;
struct Node* right;
};
// Function to create a new node
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
// Function to search for a value in the BST
struct Node* search(struct Node* root, int data) {
// Base case: root is null or data is present at root
if (root == NULL || root->data == data)
return root;
// If data is less than the root, search in the left subtree
if (data < root->data)
return search(root->left, data);
// If data is greater than the root, search in the right subtree
return search(root->right, data);
}
Time Complexity of Search Operation:
Best Case: O(1) (the element is found at the root).
Average Case: O(logn) (in a balanced BST).
Worst Case: O(n) (in an unbalanced BST, where the tree resembles a linked list).
Insertion Operation in BST
The insertion operation in a BST maintains the ordering property. The new value is compared to the current node, and the algorithm moves left or right accordingly, similar to the search operation:
If the value to insert is less than the current node, the left subtree is explored.
If the value to insert is greater than the current node, the right subtree is explored.
Once a NULL position is found (an empty left or right child), the new node is inserted at that position.
C Code for Inserting a Node in a BST
// Function to insert a node into a BST
struct Node* insert(struct Node* node, int data) {
// Base case: If the tree is empty, return a new node
if (node == NULL)
return createNode(data);
// Recur down the tree
if (data < node->data)
node->left = insert(node->left, data);
else if (data > node->data)
node->right = insert(node->right, data);
// Return the unchanged node pointer
return node;
}
Time Complexity of Insertion Operation:
Best Case: O(1) (the element is inserted at the root or close to the root).
Average Case: O(logn) (in a balanced BST).
Worst Case: O(n) (in an unbalanced BST).
Deletion Operation in BST
The deletion operation in a BST is more complex, as it must maintain the ordering property of the tree after removing a node. There are three cases to consider:
Node to be deleted has no children (leaf node): Simply remove the node.
Node to be deleted has one child: Remove the node and replace it with its child.
Node to be deleted has two children: Find the node's in-order successor (smallest value in the right subtree) or in-order predecessor (largest value in the left subtree), copy its value to the current node, and delete the successor/predecessor.
C Code for Deleting a Node in a BST
// Function to find the node with the minimum value in a tree (in-order successor)
struct Node* findMin(struct Node* node) {
struct Node* current = node;
while (current && current->left != NULL)
current = current->left;
return current;
}
// Function to delete a node from a BST
struct Node* deleteNode(struct Node* root, int data) {
if (root == NULL)
return root;
// Recur down the tree to find the node to be deleted
if (data < root->data)
root->left = deleteNode(root->left, data);
else if (data > root->data)
root->right = deleteNode(root->right, data);
else {
// Node to be deleted found
// Case 1: Node has no children (leaf node)
if (root->left == NULL && root->right == NULL) {
free(root);
return NULL;
}
// Case 2: Node has one child
if (root->left == NULL) {
struct Node* temp = root->right;
free(root);
return temp;
}
if (root->right == NULL) {
struct Node* temp = root->left;
free(root);
return temp;
}
// Case 3: Node has two children
// Find the in-order successor (smallest in the right subtree)
struct Node* temp = findMin(root->right);
// Copy the in-order successor's value to this node
root->data = temp->data;
// Delete the in-order successor
root->right = deleteNode(root->right, temp->data);
}
return root;
}
Time Complexity of Deletion Operation:
Best Case: O(1) (the node to delete is a leaf or close to the root).
Average Case: O(logn) (in a balanced BST).
Worst Case: O(n) (in an unbalanced BST).
Time Complexity Analysis of BST Operations
The time complexity of BST operations depends on the height of the tree. In a balanced BST, the height is O(logn), leading to logarithmic time complexity for all operations. However, in the worst case (unbalanced BST), the height can be O(n), leading to linear time complexity.
| Operation | Best Case | Average Case | Worst Case |
| Search | O(1) | O(logn) | O(n) |
| Insertion | O(1) | O(logn) | O(n) |
| Deletion | O(1) | O(logn) | O(n) |
Balanced BSTs: Maintain a tree structure with height O(logn), leading to efficient operations.
Unbalanced BSTs: When the tree becomes skewed (resembles a linked list), the height can degrade to O(n), making operations inefficient.
Balanced Binary Trees
Need for Balanced Trees
A balanced binary tree is a binary tree in which the height difference between the left and right subtrees of any node is bounded by a small constant (commonly 1). The need for balanced trees arises from the following considerations:
Efficient Operations: In an unbalanced binary tree, operations such as insertion, deletion, and search can degrade to linear time complexity (O(n)), as the tree may become skewed (e.g., resembling a linked list). In contrast, a balanced tree ensures that the height of the tree remains logarithmic relative to the number of nodes, leading to (O(\log n)) time complexity for these operations.
Space Utilization: Balanced trees make better use of memory since they avoid long chains of nodes in one direction, minimizing the number of empty branches and wasted space.
Comparison Between Unbalanced and Balanced Binary Trees
| Aspect | Unbalanced Binary Tree | Balanced Binary Tree |
| Height | Can grow to (O(n)) in the worst case (linked-list-like structure). | Height is maintained at (O(\log n)) by balancing operations. |
| Time Complexity | Operations degrade to (O(n)) due to increased height. | Operations remain (O(\log n)) due to balanced structure. |
| Structure | Can become skewed or degenerate, with long chains of nodes. | Nodes are distributed more evenly, leading to better performance. |
| Use Case | Suitable for small datasets where performance is less critical. | Necessary for large datasets and performance-critical applications. |
AVL Trees
An AVL tree is a type of self-balancing binary search tree where the height of the left and right subtrees of every node differs by at most 1. Named after its inventors, Adelson-Velsky and Landis, AVL trees ensure that the tree remains balanced after every insertion and deletion operation by performing rotations.
Balance Factor: The balance factor of a node in an AVL tree is defined as the difference in height between its left and right subtrees: \(\text{Balance Factor} = \text{Height of Left Subtree} - \text{Height of Right Subtree}\) For a node to be balanced, its balance factor must be -1, 0, or 1.
Height: In an AVL tree, the height of the tree is maintained at (O(\log n)).
AVL Rotations: Single and Double Rotations
To maintain balance, AVL trees perform rotations whenever an insertion or deletion operation violates the AVL property (i.e., balance factor exceeds 1 or -1). There are four types of rotations, two of which are single rotations and two are double rotations:
Single Right Rotation (LL Rotation): Occurs when a left-heavy node has a left-heavy left child.
Single Left Rotation (RR Rotation): Occurs when a right-heavy node has a right-heavy right child.
Double Left-Right Rotation (LR Rotation): Occurs when a left-heavy node has a right-heavy left child.
Double Right-Left Rotation (RL Rotation): Occurs when a right-heavy node has a left-heavy right child.
Single Rotations
Right Rotation (LL Rotation):
Applied when the left subtree of a node is unbalanced (balance factor > 1), and the left child of the node also has a balance factor of 1 or 0 (left-heavy).
This rotation is used to move the left child up and the root node down to the right.
Example:
Before rotation (LL Case):
30
/
20
/
10
After rotation:
20
/ \
10 30
C Code for Right Rotation:
struct Node* rightRotate(struct Node* y) {
struct Node* x = y->left;
struct Node* T2 = x->right;
// Perform rotation
x->right = y;
y->left = T2;
// Return new root
return x;
}
Left Rotation (RR Rotation):
Applied when the right subtree of a node is unbalanced (balance factor < -1), and the right child of the node also has a balance factor of -1 or 0 (right-heavy).
This rotation moves the right child up and the root node down to the left.
Example:
Before rotation (RR Case):
10
\
20
\
30
After rotation:
20
/ \
10 30
C Code for Left Rotation:
struct Node* leftRotate(struct Node* x) {
struct Node* y = x->right;
struct Node* T2 = y->left;
// Perform rotation
y->left = x;
x->right = T2;
// Return new root
return y;
}
Double Rotations
Left-Right Rotation (LR Rotation):
Occurs when a node is left-heavy, but its left child is right-heavy.
This requires a left rotation on the left child, followed by a right rotation on the root.
Example:
Before LR Rotation:
30
/
10
\
20
After rotation:
20
/ \
10 30
Right-Left Rotation (RL Rotation):
Occurs when a node is right-heavy, but its right child is left-heavy.
This requires a right rotation on the right child, followed by a left rotation on the root.
Example:
Before RL Rotation:
10
\
30
/
20
After rotation:
20
/ \
10 30
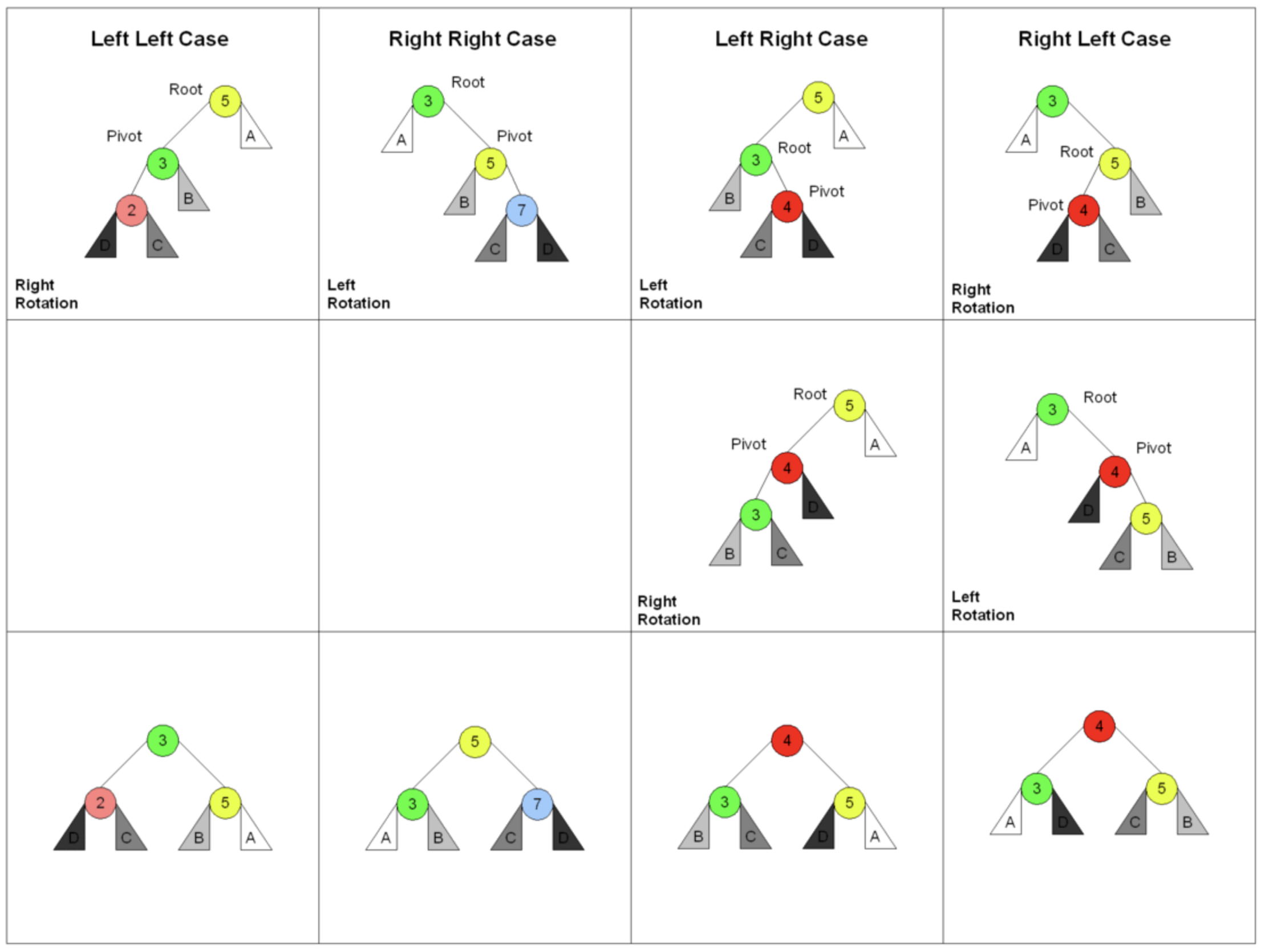
AVL Tree Operations (Insertion, Deletion, and Rotations)
1. Insertion in an AVL Tree
Insertion in an AVL tree is similar to insertion in a binary search tree, but after the insertion, we must check the balance factor of the nodes and perform rotations if necessary.
C Code for Inserting a Node in an AVL Tree
// Function to get the height of the tree
int height(struct Node* node) {
if (node == NULL)
return 0;
return node->height;
}
// Function to calculate the balance factor
int getBalance(struct Node* node) {
if (node == NULL)
return 0;
return height(node->left) - height(node->right);
}
// Function to insert a node into the AVL tree
struct Node* insert(struct Node* node, int data) {
// Perform normal BST insertion
if (node == NULL)
return createNode(data);
if (data < node->data)
node->left = insert(node->left, data);
else if (data > node->data)
node->right = insert(node->right, data);
else // Equal data is not allowed in BST
return node;
// Update the height of this ancestor node
node->height = 1 + max(height(node->left), height(node->right));
// Get the balance factor to check whether this node became unbalanced
int balance = getBalance(node);
// If the node is unbalanced, there are 4 cases
// Case 1: Left Left (LL)
if (balance > 1 && data < node->left->data)
return rightRotate(node);
// Case 2: Right Right (RR)
if (balance < -1 && data > node->right->data)
return leftRotate(node);
// Case 3: Left Right (LR)
if (balance > 1 && data > node->left->data) {
node->left = leftRotate(node->left);
return rightRotate(node);
}
// Case 4: Right Left (RL)
if (balance < -1 && data < node->right->data) {
node->right = rightRotate(node->right);
return leftRotate(node);
}
// Return the unchanged node pointer
return node;
}
2. Deletion in an AVL Tree
Deletion in an AVL tree is similar to deletion in a binary search tree. After deleting the node, we must update the balance factors and perform necessary rotations to maintain the AVL property.
C Code for Deleting a Node in an AVL Tree
The deletion process follows the same logic as the insertion process, but after deleting the node, the balance factor of the ancestors is checked, and rotations are performed if needed.
struct Node* deleteNode(struct Node* root, int data) {
if (root == NULL)
return root;
// Perform standard BST deletion
if (data < root->data)
root->left = deleteNode(root->left, data);
else if (data > root->data)
root->right = deleteNode(root->right, data);
else {
// Node to be deleted found
if (root->left == NULL || root->right == NULL) {
struct Node* temp = root->left ? root->left : root->right;
if (temp == NULL) {
temp = root;
root = NULL;
} else
*root = *temp; // Copy the contents of the non-empty child
free(temp);
} else {
struct Node* temp = findMin(root->right);
root->data = temp->data;
root->right = deleteNode(root->right, temp->data);
}
}
if (root == NULL)
return root;
// Update height
root->height = 1 + max(height(root->left), height(root->right));
// Check the balance factor
int balance = getBalance(root);
// Perform rotations if the node is unbalanced
// LL case
if (balance > 1 && getBalance(root->left) >= 0)
return rightRotate(root);
// LR case
if (balance > 1 && getBalance(root->left) < 0) {
root->left = leftRotate(root->left);
return rightRotate(root);
}
// RR case
if (balance < -1 && getBalance(root->right) <= 0)
return leftRotate(root);
// RL case
if (balance < -1 && getBalance(root->right) > 0) {
root->right = rightRotate(root->right);
return leftRotate(root);
}
return root;
}
Threaded Binary Trees
Single and Double-Threaded Binary Trees
In a threaded binary tree, null pointers in a binary tree (left or right pointers that don't have a child) are replaced with "threads." These threads allow for easier and more efficient traversal of the tree without needing a stack or recursion.
Single-Threaded Binary Tree: In a single-threaded binary tree, each node's right pointer is repurposed to store a thread that points to its in-order successor if there is no right child. This facilitates in-order traversal.
Double-Threaded Binary Tree: In a double-threaded binary tree, both the left and right pointers can be used as threads. The left thread points to the in-order predecessor when there is no left child, and the right thread points to the in-order successor when there is no right child. This structure allows efficient bi-directional in-order traversal.
Purpose of Threaded Trees
The main purpose of threaded binary trees is to optimize tree traversal, especially in-order traversal. In a traditional binary tree, recursive or iterative methods with additional data structures (such as a stack) are used to traverse the tree. In a threaded tree, threads provide a direct way to move to the next node in sequence without the need for recursion or a stack, making traversal more efficient.
Implementation of a Single-Threaded Binary Tree
In a single-threaded binary tree, the right pointer of a node points to the in-order successor when there is no right child. To implement this, we need to modify the tree node structure.
C Code for a Single-Threaded Binary Tree:
#include <stdio.h>
#include <stdlib.h>
// Structure for a threaded binary tree node
struct Node {
int data;
struct Node* left;
struct Node* right;
int isThreaded; // 1 if right pointer is a thread, 0 if it points to a child
};
// Function to create a new node
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
newNode->isThreaded = 0;
return newNode;
}
// In-order traversal in a threaded binary tree
void inOrder(struct Node* root) {
struct Node* current = root;
// Go to the leftmost node
while (current->left != NULL)
current = current->left;
// Traverse the tree
while (current != NULL) {
printf("%d ", current->data);
// If this is a threaded node, follow the thread
if (current->isThreaded)
current = current->right;
else {
// Otherwise, find the leftmost node in the right subtree
current = current->right;
while (current != NULL && current->left != NULL)
current = current->left;
}
}
}
In this example, the isThreaded flag is used to check whether the right pointer is a thread or a pointer to a right child.
Performance Advantages of Threaded Binary Trees
In-Order Traversal Without Stack or Recursion: Traditional in-order traversal uses either recursion (with function call overhead) or an explicit stack. Threaded binary trees eliminate the need for these by using threads to directly access the in-order successor, improving traversal efficiency.
Space Efficiency: Since threaded binary trees repurpose null pointers, they make better use of memory by reducing wasted space in leaf nodes.
Faster Traversal: In scenarios where repeated in-order traversals are required, threaded trees can significantly speed up traversal time because they avoid the overhead of maintaining an additional stack or recursive call chain.
B-Trees
A B-tree is a balanced search tree designed to efficiently handle large amounts of data stored on disk. B-trees are widely used in databases and file systems due to their ability to minimize disk I/O operations while maintaining balanced structure. A B-tree is a generalization of a binary search tree, where each node can have more than two children. The primary objective of a B-tree is to keep data balanced and reduce the height of the tree to ensure efficient data retrieval, insertion, and deletion.
Key Properties of B-Trees
Multiple Keys Per Node: Unlike binary trees, where each node stores a single key, B-tree nodes can store multiple keys. This reduces the height of the tree and ensures that searching, inserting, and deleting can be performed in logarithmic time.
Variable Number of Children: A B-tree node can have a variable number of child nodes (determined by the order of the B-tree). A node with ( n ) keys will have ( n+1 ) children.
Balanced Tree: B-trees maintain balance by ensuring that all leaf nodes are at the same depth. This guarantees that search, insertion, and deletion operations are always efficient.
Minimization of Disk Access: B-trees are optimized for scenarios where large data sets are stored on disk. By keeping nodes densely populated with keys, the number of disk reads is minimized, making data access faster.
Structure of a B-Tree
A B-tree of order ( m ) (where ( m ) is the maximum number of children) has the following properties:
Every node has at most ( m ) children.
Every node except the root has at least ( \lceil m/2 \rceil ) children.
The root has at least 2 children if it is not a leaf.
All leaves appear on the same level.
Every node contains ( k ) keys, where ( \lceil m/2 - 1 \rceil \leq k \leq m - 1 ).
Example of a B-Tree (Order 4)
Consider a B-tree of order 4. Each node can have at most 3 keys and 4 children.
[10 | 20 | 30]
/ | | \
/ | | \
[5 | 7] [12] [22 | 25] [35 | 40 | 45]
The root node contains 3 keys (10, 20, and 30).
The root node has 4 children, where each child node contains between 1 and 3 keys.
Operations on B-Trees
Search: Searching in a B-tree is similar to searching in a binary search tree, but with multiple keys in each node. The search process compares the target value with the keys in the node and recursively descends into the appropriate child.
Insertion: Insertion into a B-tree involves adding a key to the appropriate node. If the node exceeds the maximum number of keys, it is split, and the middle key is promoted to the parent. This split may propagate up the tree, ensuring balance is maintained.
Deletion: Deletion in a B-tree is more complex. It involves removing the key from the appropriate node. If this causes the node to have too few keys, nodes may need to be merged or redistributed to maintain the B-tree properties.
Use of B-Trees in Databases and File Systems
Databases: B-trees are commonly used to implement indexes in databases. By keeping the height of the tree low and minimizing disk I/O, B-trees ensure efficient searching, insertion, and deletion of database records.
File Systems: Many modern file systems, such as NTFS (Windows) and HFS+ (macOS), use B-trees to store metadata about files and directories. The balanced structure of B-trees allows file systems to quickly locate files and directories, even on large disks.
Key Properties That Distinguish B-Trees from Binary Trees
| Feature | Binary Trees | B-Trees |
| Children Per Node | Each node has at most 2 children. | Each node can have multiple children (up to ( m ) for order ( m )). |
| Keys Per Node | Each node stores 1 key. | Each node stores multiple keys. |
| Height | Height can grow with the number of nodes. | Height is kept low by storing multiple keys per node. |
| Balancing | Can be unbalanced (e.g., binary search trees). | Always balanced; all leaf nodes are at the same level. |
| Use Case | Efficient for in-memory data. | Optimized for disk-based storage (databases, file systems). |
| Disk Access Optimization | No specific optimization for disk I/O. | Minimizes disk I/O by storing multiple keys per node. |
Exercises
In-Order Traversal of Binary Tree: Write a program that performs an in-order traversal of a binary tree using recursion. The program should print the nodes in the correct order.
Pre-Order Traversal of Binary Tree: Implement a function that performs a pre-order traversal of a binary tree, printing the nodes as they are visited. Use recursion for the implementation.
Level-Order Traversal of Binary Tree: Implement a level-order traversal (breadth-first) for a binary tree. The function should print nodes level by level, starting from the root.
Height of Binary Tree: Write a function to calculate the height of a binary tree. The height is defined as the number of edges on the longest path from the root to a leaf node.
Max and Min Node in Binary Tree: Implement two functions to find the maximum and minimum values in a binary search tree (BST). The function should traverse the tree efficiently using the properties of the BST.
Check if Two Trees are Identical: Write a function to check if two binary trees are identical. The function should return true if both trees have the same structure and the same node values, and false otherwise.
Insert and Search in a Binary Search Tree (BST): Implement insertion and search operations in a binary search tree. The program should allow for dynamic tree construction and search for specific values.
Check if a Binary Tree is Balanced: Write a program that checks if a given binary tree is height-balanced. A tree is balanced if the difference in height between the left and right subtrees of any node is no more than 1.
Check if a Binary Tree is a BST: Implement a function that checks if a binary tree is a binary search tree (BST). The function should verify that the left subtree has only smaller values and the right subtree has only larger values.
Find LCA (Lowest Common Ancestor) in a Binary Tree: Given a binary tree and two nodes, write a function to find the lowest common ancestor (LCA) of the two nodes. The LCA is the deepest node that is an ancestor of both.
Zig-Zag (Spiral) Traversal of Binary Tree: Write a function to perform a zig-zag or spiral traversal of a binary tree. The traversal should alternate between left-to-right and right-to-left at each level.
Check if Two Binary Trees are Mirror Images: Write a function to check if two binary trees are mirror images of each other. The function should return true if one tree is the mirror of the other and false otherwise.
Convert Binary Tree to Threaded Binary Tree: Convert a given binary tree into a single-threaded binary tree. Implement in-order traversal for the threaded tree without using a stack or recursion.
Find the Diameter of a Binary Tree: Write a function to compute the diameter of a binary tree. The diameter is the longest path between two nodes in the tree, which may or may not pass through the root.
AVL Tree Insertion with Balancing: Implement an AVL tree and provide the insertion operation. After each insertion, balance the tree using single and double rotations to maintain the AVL property.
Delete a Node in an AVL Tree: Write a function to delete a node in an AVL tree. Ensure that the AVL tree property (balance factor of each node is -1, 0, or 1) is maintained after the deletion using appropriate rotations.
Check if Binary Tree is Symmetric: Write a function to check if a binary tree is symmetric (i.e., it is a mirror of itself). The function should return true if the tree is symmetric and false otherwise.
Construct Binary Tree from In-Order and Pre-Order Traversals: Given the in-order and pre-order traversals of a binary tree, write a function to reconstruct the tree.
B-Tree Insertion: Implement the insertion operation for a B-tree of order (m). Ensure that nodes split appropriately when they exceed the maximum number of keys, and propagate the split upwards as necessary.
B-Tree Search: Write a function to search for a key in a B-tree. The function should traverse the tree efficiently, considering that each node contains multiple keys and multiple children.