In systems not employing deadlock-prevention or deadlock-avoidance algorithms, the risk of deadlocks—situations where processes indefinitely wait on each other for resources—becomes a tangible concern. To manage this, the system may incorporate two key mechanisms: one for detecting deadlocks when they occur and another for recovering from such states.
Deadlock Detection in Systems with Single Instances of Each Resource Type
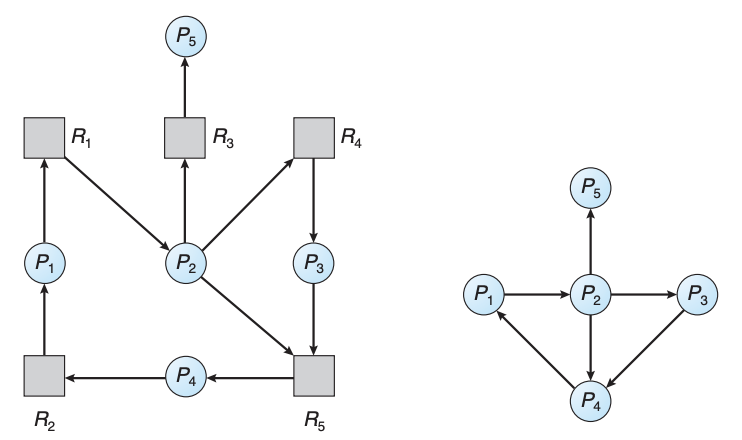
For environments where each resource type has only a single instance, a specialized deadlock detection algorithm can be utilized. This involves the use of a simplified version of the resource-allocation graph known as the "wait-for graph."
Transition to a Wait-for Graph
A wait-for graph simplifies the resource-allocation graph by focusing solely on process interactions, omitting resource nodes. In this graph:
Nodes represent processes within the system.
Directed Edges signify a waiting relationship between processes. Specifically, an edge from process Pi to process Pj indicates that Pi is waiting for a resource currently held by Pj.
This relationship in the wait-for graph corresponds directly to a scenario in the resource-allocation graph where there are two edges: one from Pi to a resource Rq (indicating Pi's request) and another from Rq to Pj (showing Rq's allocation to Pj). This abstraction removes the middleman—the resources—focusing on the deadlock-relevant aspect of processes waiting on each other.
Using the Wait-for Graph for Deadlock Detection
The core principle for detecting deadlocks using the wait-for graph hinges on searching for cycles within the graph. A cycle in this context signifies a deadlock situation: it represents a set of processes each waiting for the next in a never-ending loop, with no process able to proceed.
To effectively detect deadlocks, the system periodically:
Updates the wait-for graph to reflect the current state of process interactions and resource allocations.
Runs a cycle detection algorithm on the updated wait-for graph.
Finding a cycle in a graph generally requires computational efforts proportional to the square of the number of nodes (processes) in the graph, specifically an order of n² operations for n vertices.
Practical Implication
The transition from a resource-allocation graph to a wait-for graph and the subsequent cycle detection forms a robust mechanism for identifying deadlocks in systems where resources are uniquely instanced. By maintaining and periodically analyzing the wait-for graph, the system can pinpoint deadlock scenarios, triggering the need for subsequent recovery actions to resolve these deadlocks and restore system functionality.
In systems where multiple instances of resource types are available, a more complex approach than the wait-for graph is required for deadlock detection. This approach involves an algorithm that closely mirrors the structures used in the Banker's Algorithm, adjusted to detect rather than avoid deadlocks. Here’s an in-depth look at the data structures and steps involved in this algorithm:
Data Structures
Available: This is a vector of length m (where m represents the number of resource types), indicating the count of available instances for each resource type at the current moment.
Allocation: An n × m matrix (with n being the number of processes), where each element Allocation[i][j] represents the number of instances of resource type Rj currently allocated to process Pi.
Request: An n × m matrix showing the current requests by each process, where Request[i][j] = k means process Pi is requesting k additional instances of resource type Rj.
These structures are dynamic, changing as processes acquire, request, and release resources.
Deadlock Detection Algorithm Steps
Initialization:
- Create two vectors: Work and Finish. Work is initialized with the Available vector, reflecting the current availability of each resource type. Finish is a vector of length n, where each element corresponds to a process in the system. For each process Pi, if Allocationi (the resources currently allocated to Pi) is non-zero, set Finish[i] = false, indicating that Pi's completion status is undetermined. If Allocationi is zero, set Finish[i] = true, implying Pi has no resources and is considered finished for the purposes of this algorithm.
Search for an Eligible Process:
The algorithm looks for a process Pi such that: a. Finish[i] is false, meaning Pi is not yet marked as completed. b. Requesti ≤ Work, indicating the system has enough available resources to satisfy Pi's current request.
If no such process exists, the algorithm proceeds to step 4.
Resource Reclamation Simulation:
- Once a process satisfying the conditions in step 2 is found, the algorithm simulates the return of Pi's allocated resources to the system. This is done by updating Work = Work + Allocationi, effectively pretending that Pi has completed and returned its resources. Finish[i] is then set to true, marking Pi as completed. The algorithm then loops back to step 2 to search for another process that can complete.
Deadlock Detection:
- If, after the search, there is at least one process Pi for which Finish[i] remains false, the system is in a deadlock state, and Pi is part of the deadlock. This indicates that the system cannot allocate resources to satisfy the remaining requests without leading to a wait condition.
This algorithm offers a methodical way to assess the current allocation and request states of processes in a system, identifying deadlock scenarios by simulating the completion of processes and the reallocation of their resources. By requiring an order of m × n² operations, it systematically verifies whether the current resource distribution and pending requests can lead to a state where no further process completions are possible without external intervention, thereby detecting deadlocks.
To demonstrate the deadlock detection algorithm in a system with multiple instances of each resource type, let's analyze a system configured with five processes (P0 through P4) and three types of resources (A, B, and C), having seven, two, and six instances respectively. Initially, the allocation and request states, along with the available resources, are as follows:
Initial State:
Allocation Matrix:
A B C
P0 0 1 0
P1 2 0 0
P2 3 0 3
P3 2 1 1
P4 0 0 2
Request Matrix:
A B C
P0 0 0 0
P1 2 0 2
P2 0 0 0
P3 1 0 0
P4 0 0 2
Available Vector:
A B C
0 0 0
Given this setup, we claim that the system is not in a deadlocked state. By applying the deadlock detection algorithm:
Initialization:
- Work is initialized to Available, and Finish for each process is set based on whether they have allocations. Since P0, P1, P2, P3, and P4 have allocations, their Finish flags are initially set to false.
Executing the Algorithm:
- The algorithm identifies a sequence of process completions that leaves Finish[i] == true for all processes, confirming the system is not deadlocked. The sequence <P0, P2, P3, P1, P4> allows all processes to complete, which aligns with our initial claim.
Scenario with an Additional Request from P2:
Suppose P2 now requests an additional instance of resource type C, modifying the Request matrix:
Updated Request Matrix:
A B C
P0 0 0 0
P1 2 0 2
P2 0 0 1
P3 1 0 0
P4 0 0 2
Claim: The system enters a deadlock situation due to this additional request by P2.
Analysis:
Attempting to execute the algorithm post-request reveals that after reclaiming resources from P0 (since it has no outstanding requests), there are not enough available resources to satisfy the remaining requests of P1, P2, P3, and P4.
Specifically, the available resources after potentially reclaiming from P0 are insufficient for the next processes in line, which all have unmet requests that cannot be satisfied with the current availability.
As such, we cannot find a sequence of process completions that results in all Finish flags being true, indicating a deadlock. The processes involved in the deadlock are P1, P2, P3, and P4, as they are unable to proceed due to unmet resource requests.
The decision on when to invoke the deadlock detection algorithm hinges on the frequency of deadlocks and the extent of their impact. If deadlocks are a common occurrence, it necessitates more frequent checks to mitigate idle resources and the potential expansion of the deadlock cycle. Deadlocks arise from ungrantable immediate requests, potentially concluding a sequence of waiting processes. At its most aggressive, the detection algorithm could be employed every time a request is deferred, pinpointing not only the deadlock but also the triggering process. However, this approach is computationally intensive. A pragmatic alternative involves periodic checks, such as hourly, or triggered by specific system states, like when CPU usage falls below a certain threshold (e.g., 40%), indicating a possible deadlock due to reduced system activity. This strategy balances overhead with effectiveness, acknowledging that if the algorithm is run sporadically, identifying the initiating process in a deadlock involving multiple cycles and processes becomes challenging.
When a deadlock is detected in a system, there are several strategies for resolution, ranging from manual intervention by an operator to automated system recovery. System recovery can be approached by either aborting processes or preempting resources to disrupt the deadlock cycle.
Process Termination for Deadlock Resolution
Eliminating deadlock through process termination can be executed in two ways, each reclaiming resources from terminated processes:
Terminate all Deadlocked Processes: This approach effectively breaks the deadlock but at a significant cost. The computation done by these processes is lost, necessitating a potential redo of their tasks, which could be resource-intensive.
Terminate Processes Individually: This method involves aborting processes one at a time and running the deadlock detection algorithm after each termination to check for the persistence of deadlock. This approach, while potentially reducing the number of processes to be aborted, incurs overhead from repeatedly running the detection algorithm.
Choosing which process(es) to terminate involves a policy decision based on minimizing overall costs, which can include considerations like process priority, computational progress and remaining, resources consumed, and the process's nature (interactive or batch).
Resource Preemption as a Deadlock Solution
Alternatively, deadlocks can be resolved by preempting resources from certain processes and reallocating them to break the deadlock cycle. This method requires addressing several key issues:
Victim Selection: Identifying which processes and resources to preempt involves cost minimization, similar to process termination, and may consider factors like the resources held and the process's runtime.
Rollback: Processes from which resources are preempted must be rolled back to a safe state for restart. This rollback could be partial or total, with the latter involving restarting the process from the beginning due to challenges in identifying a precise safe state.
Preventing Starvation: Ensuring that no process is perpetually preempted and unable to complete its task is crucial. Incorporating the number of rollbacks into the decision-making process helps prevent starvation by limiting how often a process can be selected as a victim.
These recovery strategies, whether through process termination or resource preemption, require careful consideration to balance the immediate need to resolve deadlocks against the broader impact on system performance and process progress.